Este artigo fornece uma compreensão mais profunda aos usuários sobre a implementação do Data Warehouse com AWS Redshift.
O que é AWS Redshift?
AWS Redshift permite que seus usuários recuperem e manipulem os dados sem todas as configurações de um banco de dados tradicional. Ele dimensiona a capacidade de forma inteligente, dependendo dos requisitos da aplicação, fornece respostas rápidas e precisas e é totalmente gerenciado pela AWS. AWS Redshift é amplamente utilizado por suas vastas aplicações de análise de Big Data. Além disso, segue o modelo pré-pago e não incorre em cobranças adicionais quando o armazém fica ocioso:
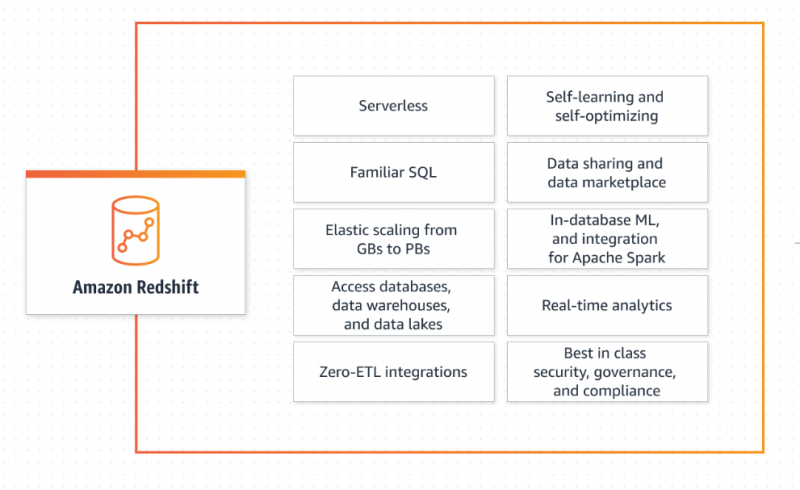
Saiba mais sobre o Redshift consultando este artigo: “Quais são os tipos de dados do Amazon Redshift” :
Como implementar armazenamento de dados com Amazon Redshift?
O Amazon Redshift usa a Standard Query Language (SQL) em diferentes armazéns para executar consultas. Extrair valores máximos enquanto monitora o custo de configuração manual de um Data Warehouse é cansativo. Portanto, o AWS Redshift acelera de maneira precisa e inteligente suas tarefas de negócios relacionadas a dados e ajuda você a acelerar seu tempo para obter insights sobre os dados de maneira rápida, fácil, confiável e segura. Há muitos benefícios na implementação do Data Warehousing com o Amazon Redshift:
- Criptografia de dados
- Otimização Inteligente
- Custo ideal
- Automatize tarefas repetitivas
- Capacidade de escalonamento automático
- Suporte para vários recursos da AWS
Abaixo estão algumas etapas nas quais podemos implementar o Data Warehousing com Amazon Redshift:
Etapa 1: criar uma função IAM
O primeiro passo na implementação de um Data Warehouse em AWS Redshift começa com a criação de uma função do IAM. Para isso, pesquise e selecione a função IAM na página Console de gerenciamento da AWS :
Clique no “Papéis” opção na barra lateral da função IAM:
Clique no “Criar função” botão próximo:
No Tipo de entidade confiável seção, clique no “Serviço AWS” enquanto estamos criando esta função IAM para o Redshift:
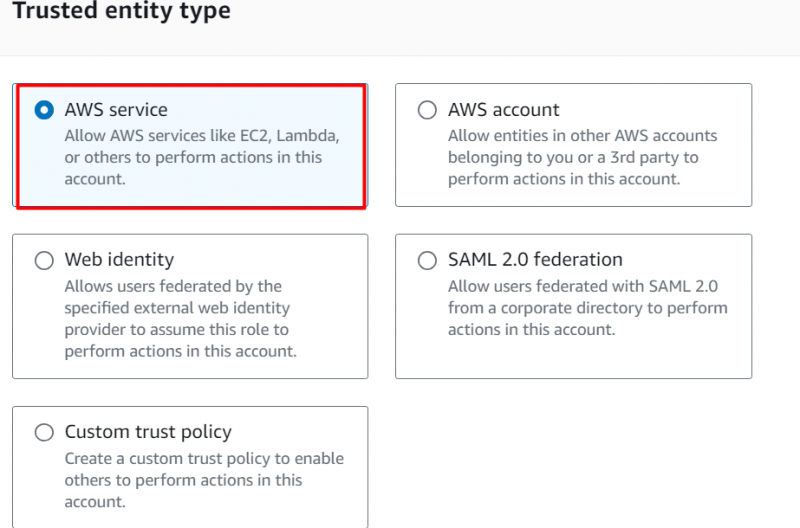
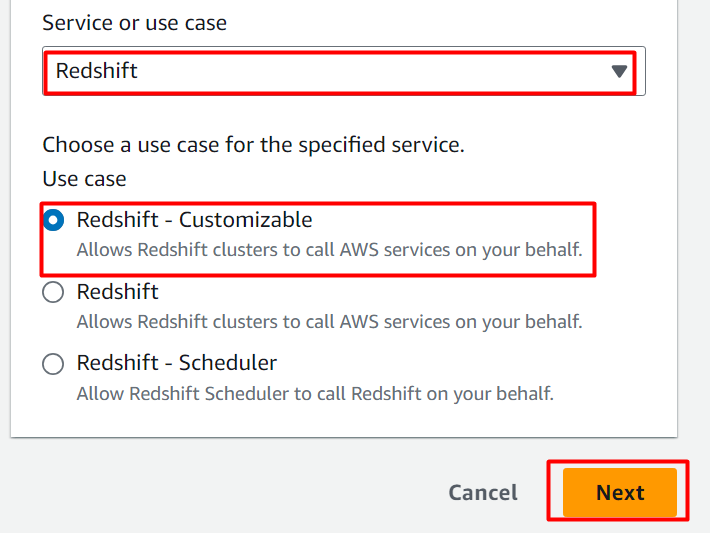
No Caso de uso seção , selecione “Desvio para o vermelho” no campo destacado e prossiga para selecionar a seguinte opção destacada. Clique no 'Próximo' botão depois:
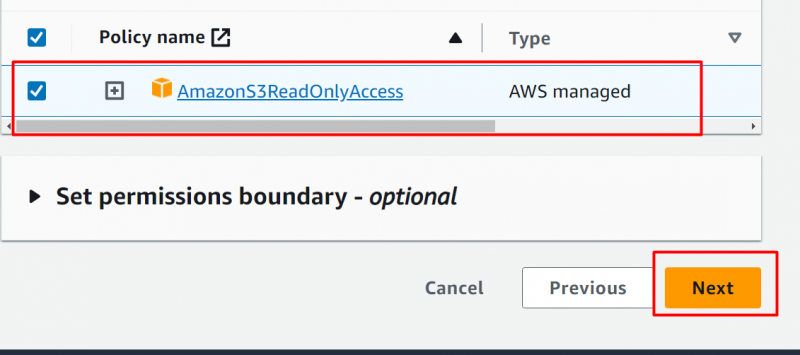
No Política de permissão seção , pesquise e selecione o “AmazonS3ReadOnlyAccess” opção. E então clique no 'Próximo' botão depois:
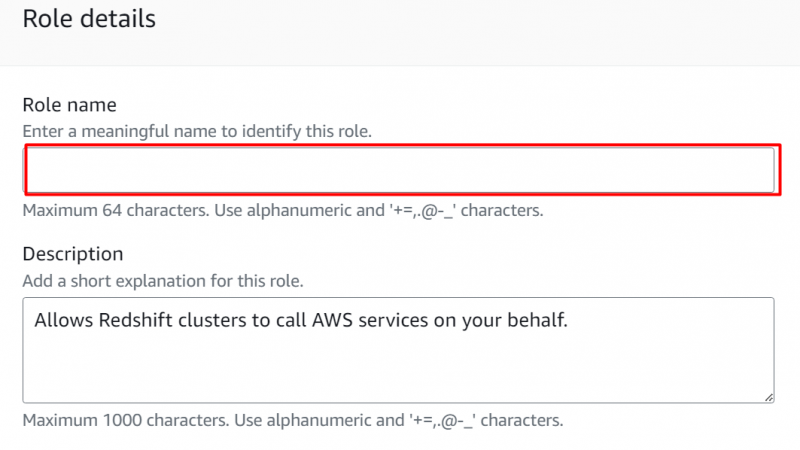
No Detalhes da função seção , forneça o nome da função:
Mantendo o resto do configurações como padrão, Clique no “Criar função” botão na parte inferior da interface:
O papel foi com sucesso criada. Clique no 'Ver função' botão:
No Ver função seção, copie o ARN e salve-o no Bloco de Notas para uso futuro:
Etapa 2: criar cluster Redshift
No AWS Management Console, pesquise e selecione o “Desvio para o vermelho” serviço:
Role para baixo “Desvio para o vermelho” console principal e clique no botão “Criar cluster” botão:
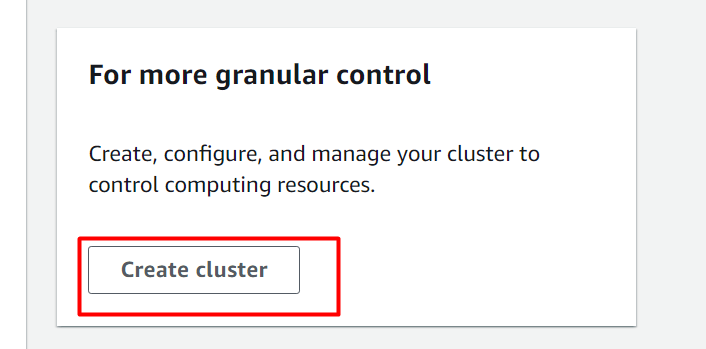
Isso navegará o usuário até o “Criar Cluster” interface. Aqui nesta interface, forneça um nome para o cluster e selecione o “dc.2 grande” para o tipo de cluster:
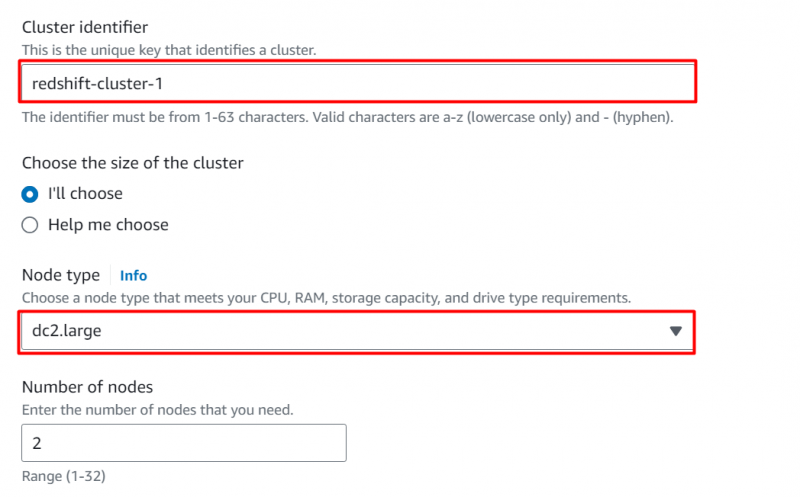
No Configurações de banco de dados seções, forneça um nome de usuário e senha para o aglomerado:
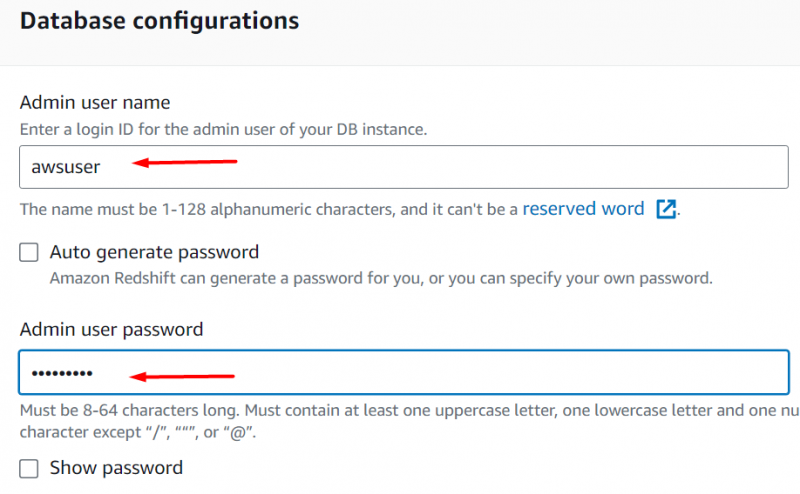
Role para baixo até Funções do IAM seção. Anexaremos aqui a função IAM que criamos anteriormente neste tutorial. Para isso, clique no “Função IAM associada” botão:
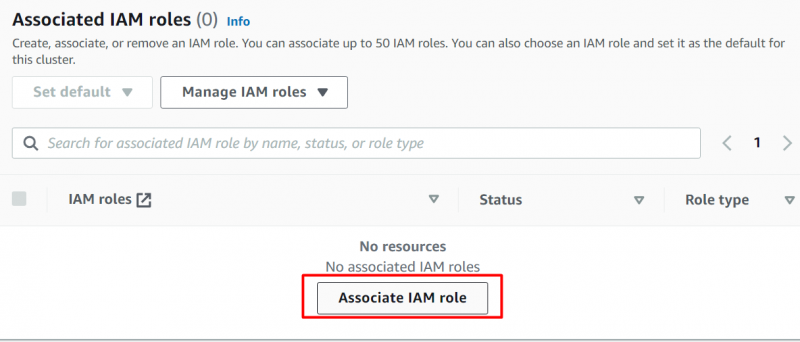
Nesta seção, selecionamos a função criada e clicamos no botão “Associar funções do IAM” botão para anexar a função:
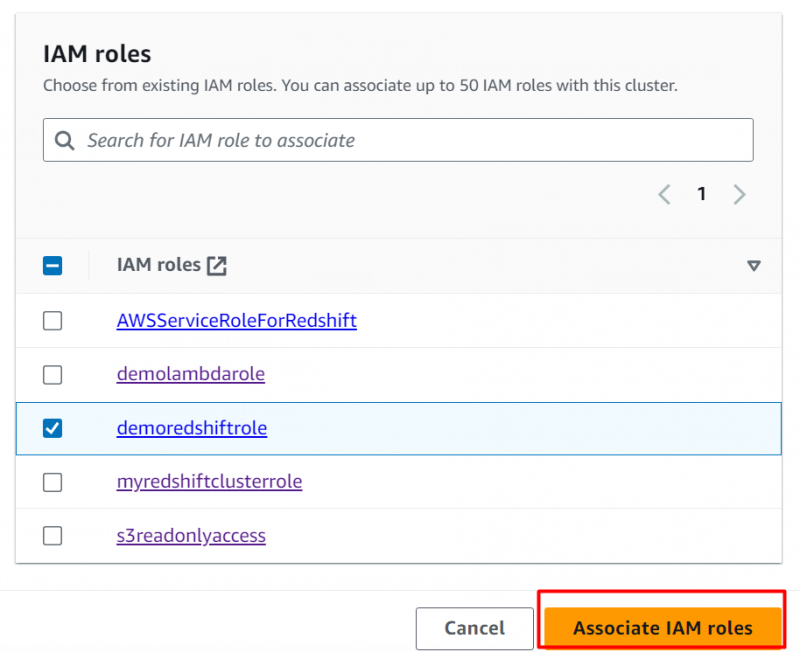
Mantendo os padrões, clique no botão “Criar cluster” botão na parte inferior da interface:
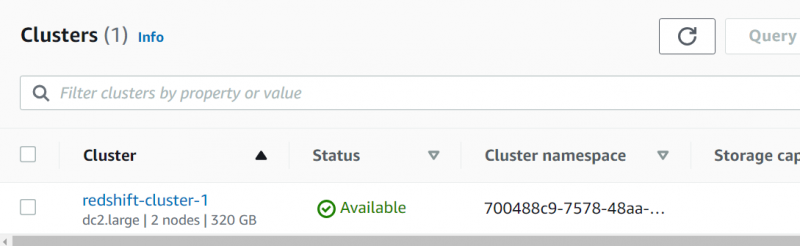
Isso levará algum tempo para que o cluster esteja disponível. Clique no nome do cluster do painel RDS depois que o status for exibido 'Ativo':
Etapa 3: adicionar permissões
Acesse o Serviço IAM do Console de gerenciamento da AWS para configurar uma nova política na conta do usuário root:
De Painel IAM, Clique no 'Usuários' opção na barra lateral esquerda:
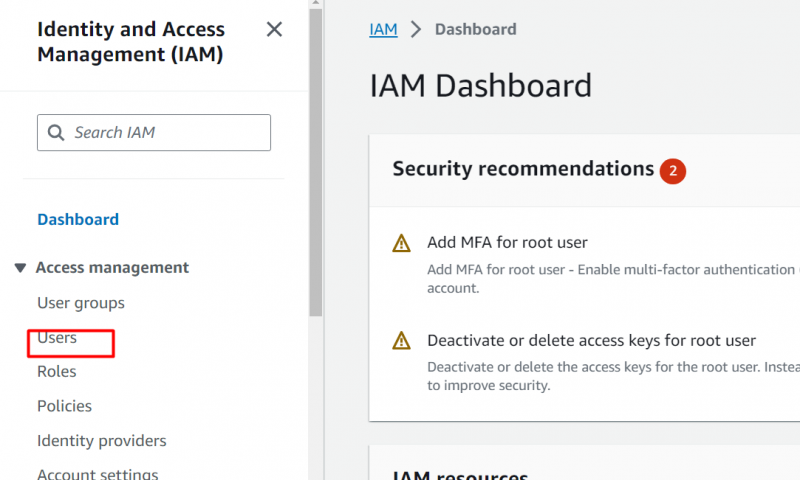
Clique no Nome do papel isso tem o acesso de administrador para a conta:
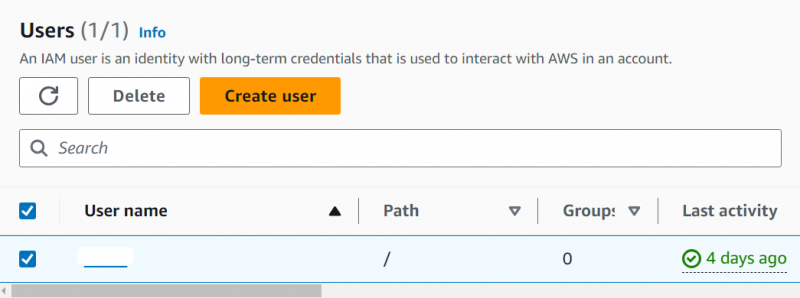
Toque em “Adicionar permissões” botão localizado na interface:
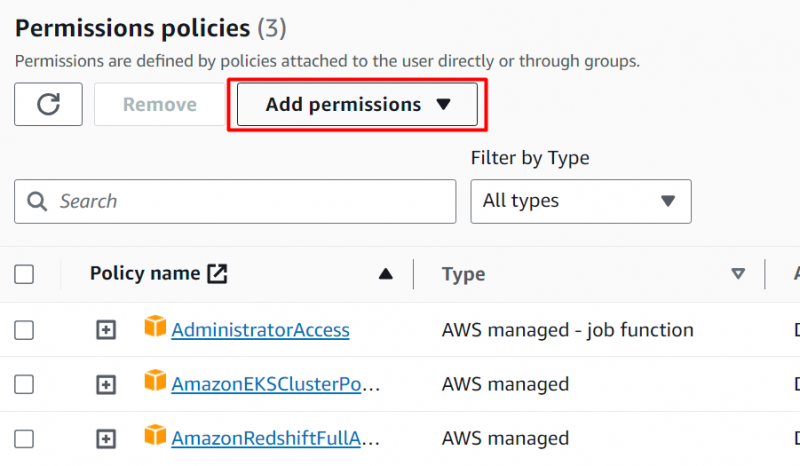
Clique no “Anexar políticas diretamente” opção sob o Opções de permissões seção:
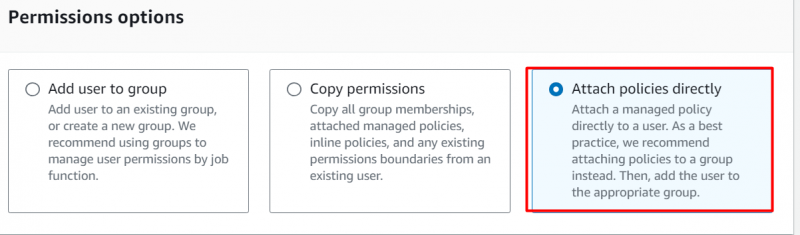
Adicione as seguintes permissões à sua conta:
- AmazonRedshiftQueryEditor
- AmazonRedshiftQueryEditorV2FullAccess
- AmazonRedshiftReadOnlyAccess
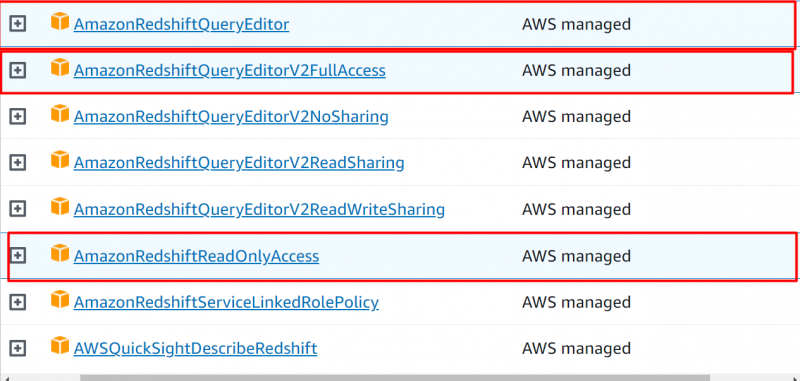
Depois de adicionar as seguintes permissões, clique no botão 'Próximo' botão:
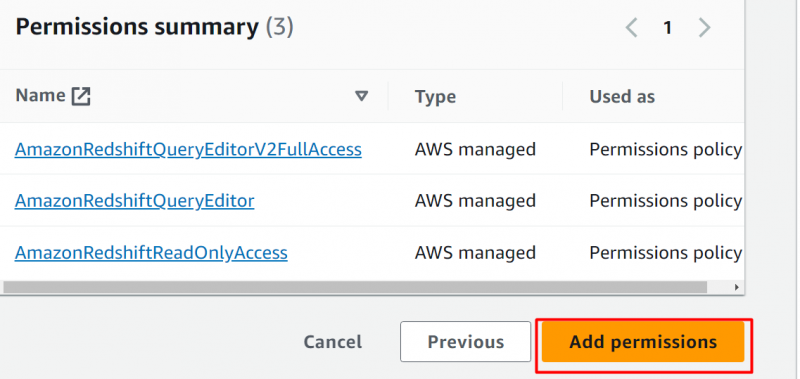
No Resumo de permissões seção, clique no “Adicionar permissões” botão:
Aqui as permissões são configuradas com sucesso:
Etapa 4: Editor de Consultas
No Painel AWS RDS , Clique no “Editor de consultas v2” opção na barra lateral:
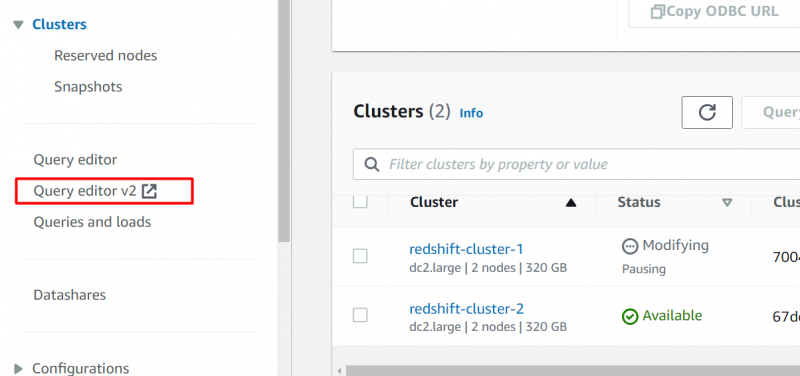
Isso exibirá a seguinte interface. Nesta interface, selecione o nome do seu cluster e forneça os seguintes detalhes para a conexão. Depois de fornecer os detalhes, clique no botão “Criar conexão” botão:
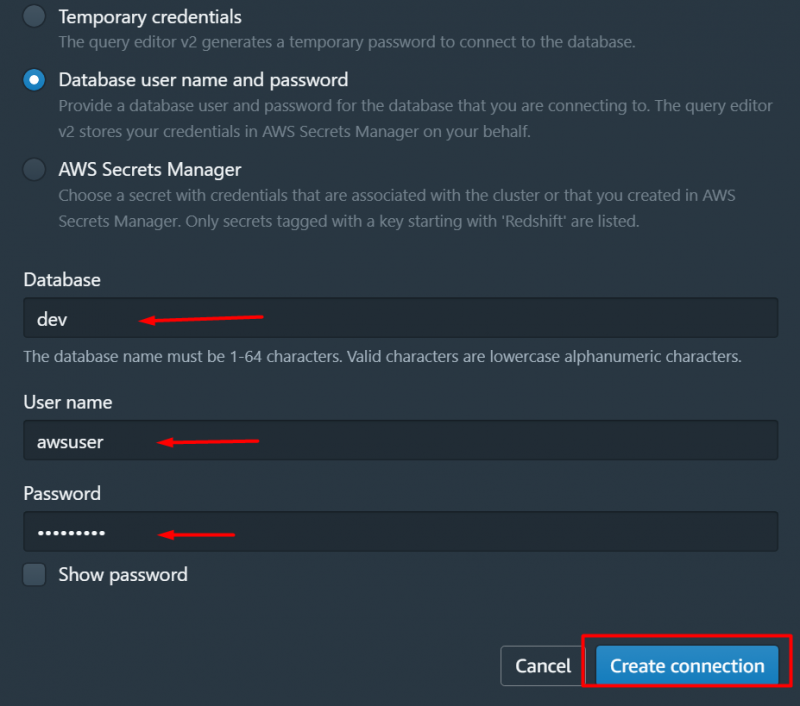
Para fins de teste, forneceremos a seguinte consulta e clicaremos no botão 'Correr' botão:
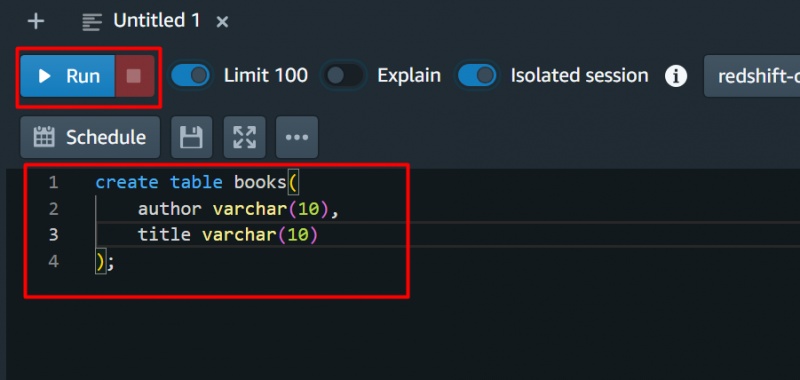
A consulta foi executada com sucesso:
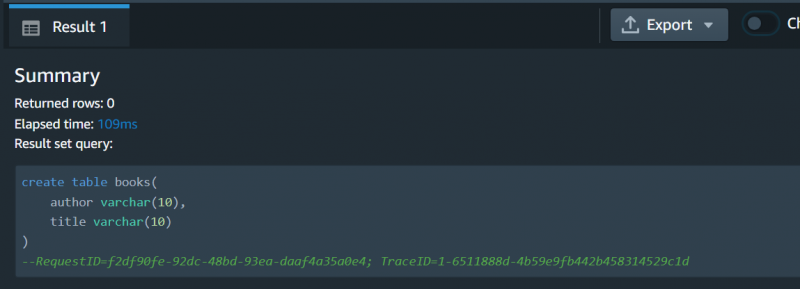
Isso é tudo deste guia. Agora o usuário pode executar diferentes consultas neste console, por exemplo, Criar, inserir, excluir, etc.
Conclusão
Para criar Data Warehousing com Redshift, configure uma função e permissão IAM com o cluster RDS e clique no botão “ Editor de consultas ”Opção para executar consultas. AWS Redshift é um banco de dados baseado em nuvem que segue a sintaxe do SQL e executa consultas em grandes conjuntos de dados de forma eficiente para alto desempenho. Este artigo fornece instruções para implementar o armazenamento de dados com o Amazon Redshift.