O Amazon Redshift é uma solução em nuvem oferecida pela AWS que atende ao propósito de um data warehouse. Um data warehouse é um grande espaço na nuvem que armazena enormes quantidades de dados. A diferença entre um data warehouse e um banco de dados é que o primeiro não armazena apenas os dados atuais, mas também o histórico completo dos dados.
Este artigo aprenderá sobre o Amazon Redshift da AWS e os tipos de dados compatíveis com esse serviço.
O que é Amazon RedShift?
É uma solução em nuvem para armazenamento de dados baseada em ‘PostgreSQL’ . Ele usa uma tecnologia chamada ‘Processamento Massivamente Paralelo (MPP)’ para processar petabytes de dados na velocidade da luz. Isso fornece uma solução fácil para previsão em tempo real com base em dados históricos e soluções de streaming.
A figura a seguir mostra o mecanismo de trabalho do Amazon Redshift:
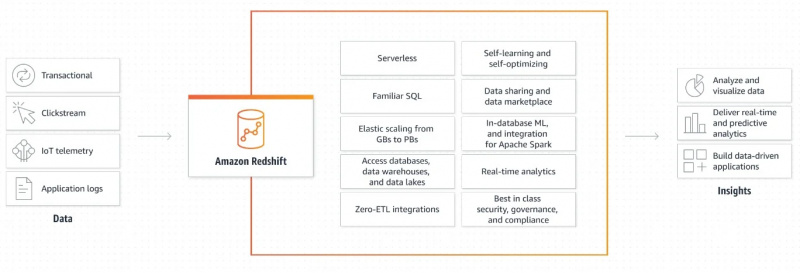
Esta explicação gráfica de como o Amazon Redshift funciona é muito simples e clara. Ele nos fornece informações sobre como os dados são recuperados e posteriormente processados para gerar saídas e criar aplicativos orientados a dados.
A arquitetura do data warehouse do Amazon Redshift também pode ser vista na figura abaixo:
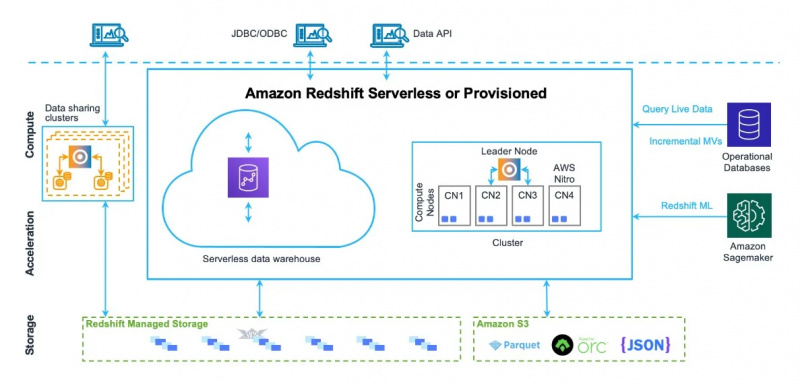
Agora, iremos para os usos e recursos deste serviço.
Características
Como já mencionado, o Amazon Redshift é baseado em PostgreSQL e usa uma tecnologia chamada Massively Parallel Processing, que permite processar petabytes de dados rapidamente. Portanto, o Redshift oferece um bom número de recursos e usos. Algumas dessas características estão abaixo:
- Segurança de Dados e Criptografia.
- Analista de negócios.
- Suporte a aplicativos orientados a dados.
- Análise preditiva.
- Repetição automatizada de tarefas.
- Dimensionamento de dados simultâneos.
- Armazenamento de dados.
Alguns recursos extras deste serviço podem ser vistos na figura abaixo:
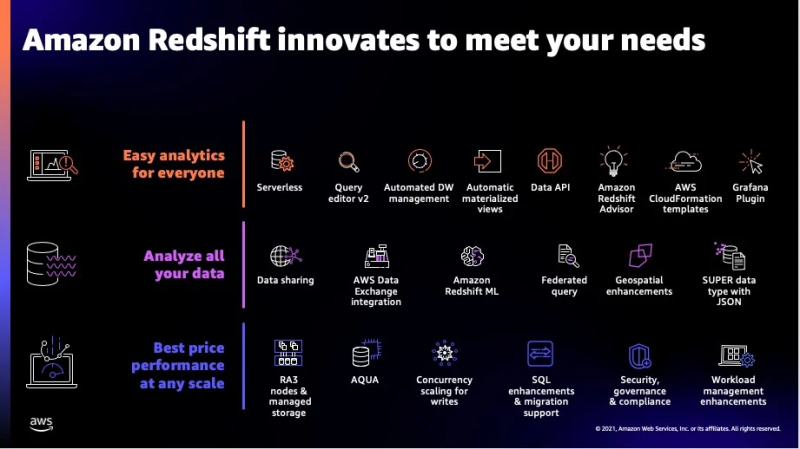
Esses foram os principais recursos que o Redshift oferece e agora passaremos para os tipos de dados suportados por esse serviço.
Tipos de dados
O Amazon Redshift é uma solução de armazenamento de dados com um grande número de recursos. Ele suporta tipos de dados estruturados e não estruturados. Por ser baseado em PostgreSQL, os dados podem ser manipulados por meio de consultas SQL simples.
Agora, surge outra questão, ou seja, como esses formatos de dados diferem entre si? Vamos discutir esses dois formatos de dados.
Dados Estruturados
Um tipo de dados altamente formatado que é facilmente traduzido por algoritmos de aprendizado de máquina é chamado de dados estruturados. Um banco de dados SQL trabalha com dados estruturados. Dados estruturados estão em formato tabular, como dados usados por bancos de dados relacionais
Um dos sistemas de gerenciamento de banco de dados SQL amplamente utilizados é o MYSQL. Sua arquitetura pode ser vista abaixo na figura dada:
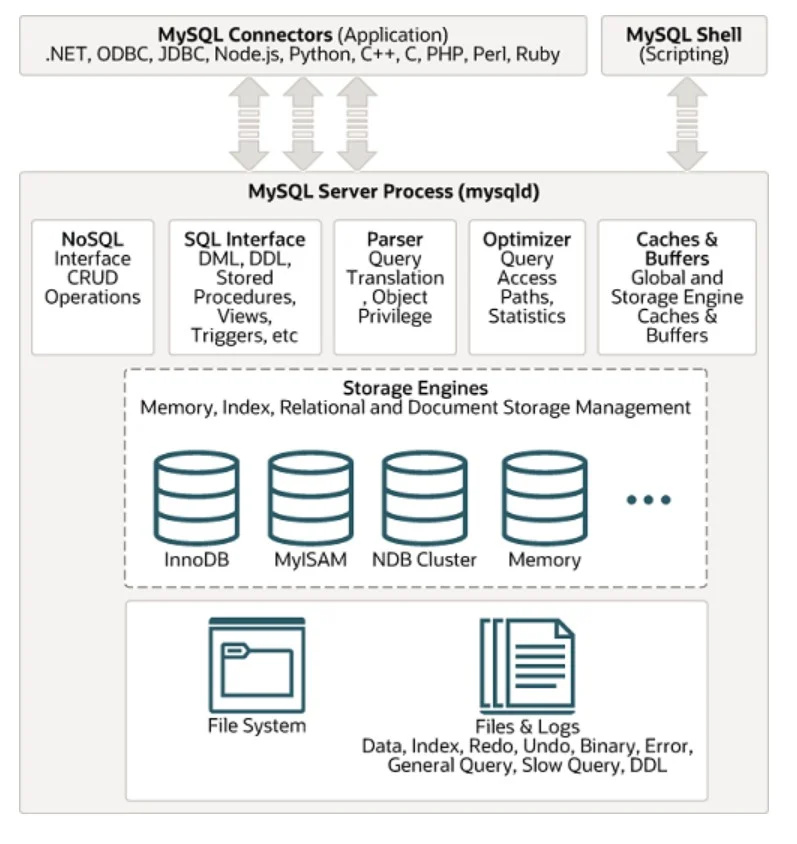
Dados não estruturados
Dados não estruturados são menos padronizados e menos formatados, como dados usados em bancos de dados não relacionais. MongoDB é um famoso banco de dados não relacional. As consultas SQL não funcionam em bancos de dados não relacionais, portanto, esses bancos de dados também são chamados de bancos de dados NoSQL.
Como já mencionado, o MongoDB é um sistema de gerenciamento de banco de dados não estruturado e sua arquitetura pode ser vista na figura abaixo:
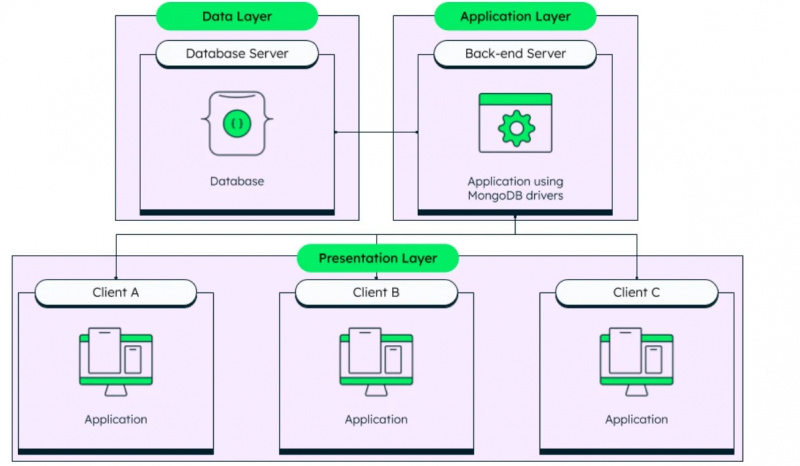
Passamos pelos dois tipos de dados fundamentais usados em bancos de dados e agora iremos para os tipos de dados reais que são compatíveis com o Amazon Redshift. Esses tipos de dados são:
- Dados Numéricos
- Dados do personagem
- Dados de data e hora
- Dados Booleanos
- Dados HLLSKETCH
- Dados SUPER
- Dados de SUBSTITUIÇÃO
Vamos discutir esses tipos de dados:
Dados Numéricos
Este tipo de dados é auto-explicativo. Ele oferece suporte a dados que estão na forma de números inteiros, decimais, ponto flutuante e outros tipos de dados numéricos.
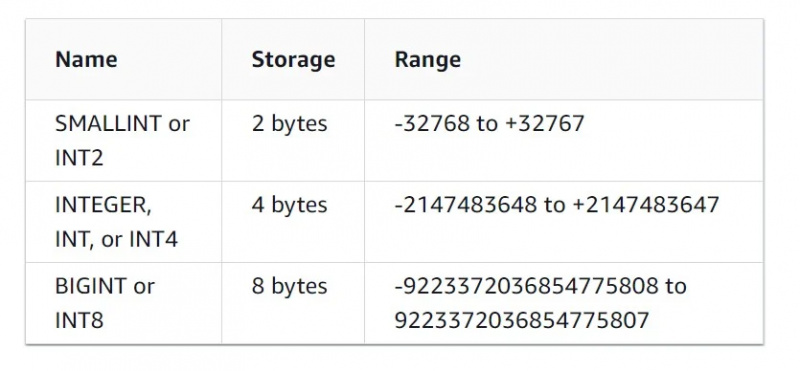
As características do tipo de dado inteiro podem ser vistas na figura abaixo:
O tipo de dados decimal armazena os dados com base na precisão do usuário. Suas características são as seguintes:

Dados do personagem
Os tipos de dados CHAR e VARCHAR se enquadram na categoria de tipos de dados baseados em caracteres. NCHAR e NVARCHAR também são tipos de dados de tipo de caractere. Ao contrário de CHAR e VARCHAR, esses dois tipos de dados armazenam caracteres Unicode de comprimento fixo. Vejamos as propriedades desses tipos de dados, como:
- CHAR, CHARACTER, NCHAR têm um alcance de 4KB.
- VARCHAR, NVARCHAR tem um alcance de 64KB.
- BPCHAR tem um intervalo de 256 Bytes.
- TEXT tem um intervalo de 260 Bytes.
Dados de data e hora
Os tipos de dados Datetime são DATE, TIME, TIMETZ,TIMESTAMP, TIMESTAMPTZ. Os recursos funcionais desses tipos de dados são os seguintes:
- DATE simplesmente armazena as datas do calendário.
- TIME armazena a hora sem referência a nenhum fuso horário. É UTC, por padrão.
- TIMETZ armazena a hora em referência ao fuso horário. É UTC nas tabelas de usuário e nas tabelas de sistema, por padrão.
- TIMESTAMP não inclui apenas o tempo, mas também as datas. É UTC tanto nas tabelas de usuário quanto nas tabelas de sistema, por padrão.
- TIMESTAMPTZ não inclui apenas o tempo, mas também as datas. É UTC apenas em tabelas de usuários, por padrão.
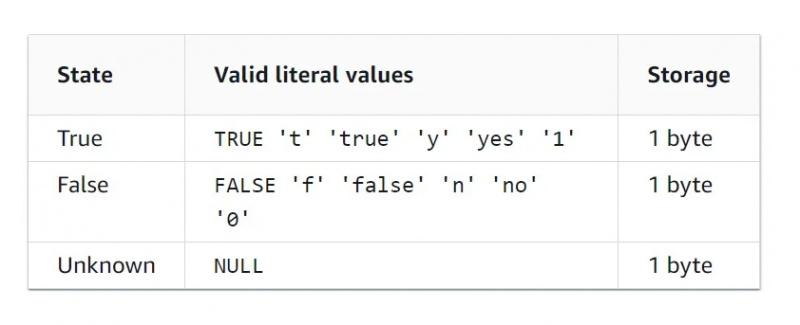
Dados Booleanos
O tipo de dados booleano é um tipo de dados binário, o que significa que existem apenas dois valores. A tabela de características para o tipo de dados booleano é fornecida abaixo na figura:
Dados HLLSKETCH
Este tipo de dados é usado para armazenar esboços. Redshift pode representar os esboços em forma esparsa ou densa. Os esboços começam como esparsos e gradualmente se tornam densos quando um formato denso fornece mais eficiência seguindo o link.
Dados SUPER
Esse tipo de dados lida com dados não estruturados que podem estar na forma de matrizes, estruturas aninhadas ou JSON. Não há modelo ou formato dos dados. Os usuários podem explorar mais informações navegando no link.
Dados de SUBSTITUIÇÃO
Esse tipo de dados também armazena caracteres. No entanto, o comprimento é limitado. O Amazon Redshift permite a conversão de dados VARBYTE em qualquer tipo de número inteiro ou dados de tipo de caractere. Para obter mais informações sobre este tipo de dados, siga o link abaixo.
Isso é tudo sobre o Amazon Redshift e os tipos de dados compatíveis.
Conclusão
O Amazon Redshift é um serviço da AWS que, em sua forma básica, serve ao propósito de um data warehouse, mas é uma solução muito poderosa e cheia de recursos para análise e previsão. Este artigo discutiu o Redshift e os tipos de dados que ele suporta. Esses tipos de dados foram explicados brevemente junto com suas características.