Esta postagem cobre o particionamento do PostgreSQL. Discutiremos as diferentes opções de particionamento que você pode usar e daremos exemplos de como usá-las para melhor compreensão.
Como criar as partições PostgreSQL
Qualquer banco de dados pode conter inúmeras tabelas com múltiplas entradas. Para facilitar o gerenciamento, você deve particionar as tabelas, o que é uma rotina de data warehouse excelente e recomendada para otimização do banco de dados e para ajudar na confiabilidade. Você pode criar diferentes partições, incluindo lista, intervalo e hash. Vamos discutir cada um em detalhes.
1. Particionamento de lista
Antes de considerar qualquer particionamento, devemos criar a tabela que utilizaremos para as partições. Ao criar a tabela, siga a sintaxe fornecida para todas as partições:
CREATE TABLE nome_tabela(tipo_dadoscoluna1, tipo_dados coluna2) PARTITION BY
O “table_name” é o nome da sua tabela junto com as diferentes colunas que a tabela terá e seus tipos de dados. Para “partition_key”, é a coluna pela qual ocorrerá o particionamento. Por exemplo, a imagem a seguir mostra que criamos a tabela “cursos” com três colunas. Além disso, nosso tipo de particionamento é LIST e selecionamos a coluna docente como nossa chave de particionamento:

Depois que a tabela for criada, devemos criar as diferentes partições de que necessitamos. Para isso, proceda com a seguinte sintaxe:
CREATE TABLE partição_tabela PARTIÇÃO DA tabela_principal FOR VALUES IN (VALUE);Por exemplo, o primeiro exemplo na imagem a seguir mostra que criamos uma tabela de partição chamada “Fset” que contém todos os valores na coluna “faculdade” que selecionamos como nossa chave de partição cujo valor é “FSET”. Usamos uma lógica semelhante para as outras duas partições que criamos.
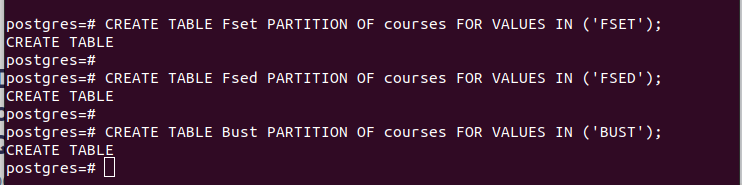
Depois de ter as partições, você pode inserir os valores na tabela principal que criamos. Cada valor inserido corresponde ao respectivo particionamento com base nos valores da chave de partição selecionada.
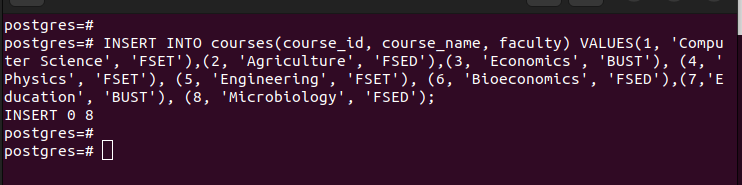
Se listarmos todas as entradas da tabela principal, podemos ver que ela contém todas as entradas que inserimos.
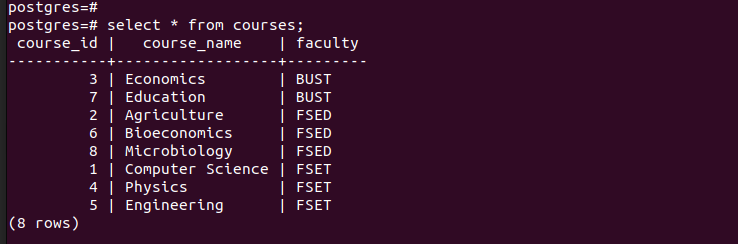
Para verificar se criamos as partições com sucesso, vamos verificar os registros em cada uma das partições criadas.
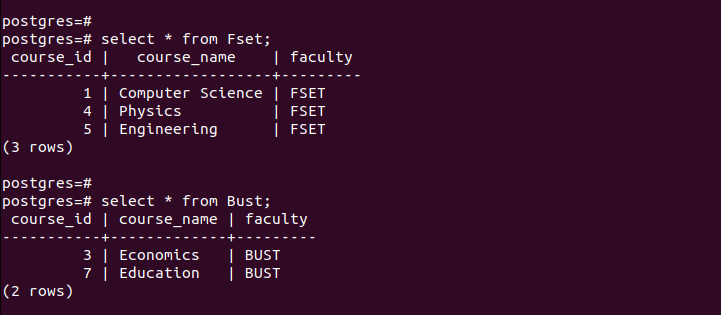
Observe como cada tabela particionada contém apenas as entradas que correspondem aos critérios definidos durante o particionamento. É assim que funciona o particionamento por lista.
2. Particionamento de intervalo
Outro critério para criação de partições é utilizar a opção RANGE. Para isso, devemos especificar os valores inicial e final a serem usados para o intervalo. Usar este método é ideal ao trabalhar com datas.
Sua sintaxe para criação da tabela principal é a seguinte:
CREATE TABLE nome_da_tabela (tipo de dados da coluna1, tipo de dados da coluna2) PARTIÇÃO POR RANGE (chave_da_partição);Criamos a tabela “cust_orders” e a especificamos para usar a data como nossa “partition_key”.

Para criar as partições, use a seguinte sintaxe:
CREATE TABLE partição_tabela PARTIÇÃO DA tabela_principal FOR VALUES FROM (valor_inicial) TO (valor_final);Definimos nossas partições para funcionarem trimestralmente usando a coluna “data”.
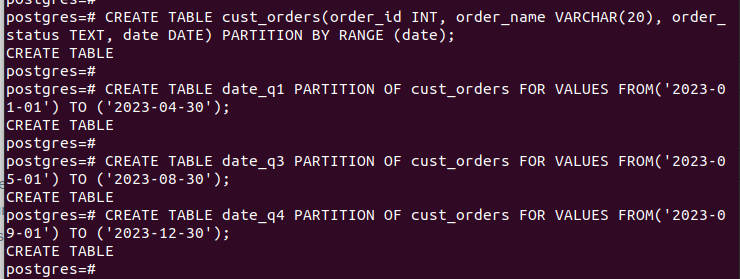
Depois de criar todas as partições e inserir os dados, nossa tabela fica assim:
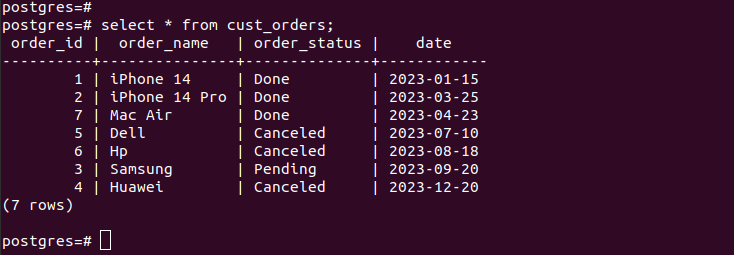
Se verificarmos as entradas nas partições criadas, verificamos se nosso particionamento funciona e só temos os registros apropriados de acordo com os critérios de particionamento que especificamos. Para todas as novas entradas adicionadas à sua tabela, elas são adicionadas automaticamente à respectiva partição.
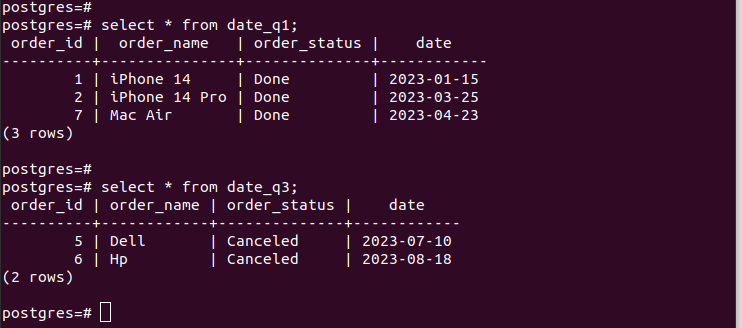
3. Particionamento de hash
O último critério de particionamento que discutiremos é o uso de hash. Vamos criar rapidamente a tabela principal usando a seguinte sintaxe:
CREATE TABLE nome_da_tabela (tipo de dados da coluna1, tipo de dados da coluna2) PARTITION BY HASH (chave_da_partição); 
Ao particionar com hash, você deve fornecer o módulo e o restante, as linhas a serem divididas pelo valor hash da “partition_key” especificada. Para o nosso caso, usamos um módulo de 4.
Nossa sintaxe é a seguinte:
CREATE TABLE partição_tabela PARTIÇÃO DA tabela_principal PARA VALORES COM (MÓDULO num1, REMAINDER num2);Nossas partições são as seguintes:
Para “main_table”, contém as entradas mostradas a seguir:
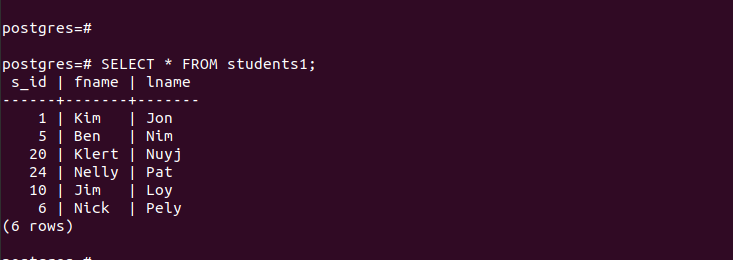
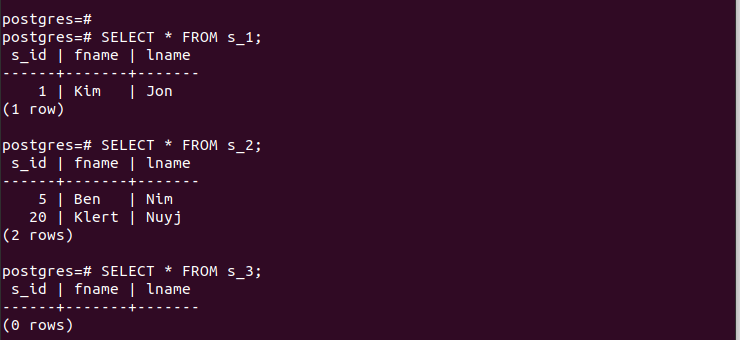
Para as partições criadas, podemos acessar suas entradas rapidamente e verificar se nosso particionamento funciona.
Conclusão
As partições PostgreSQL são uma maneira prática de otimizar o banco de dados para economizar tempo e aumentar a confiabilidade. Discutimos o particionamento em detalhes, incluindo as diferentes opções disponíveis. Além disso, fornecemos exemplos de como implementar as partições. Experimente!