Exemplo 1: Classificando o DataFrame usando o método Order() em R
A função order() em R é usada para classificar os DataFrames por uma ou várias colunas. A função order obtém os índices das linhas classificadas para reorganizar as linhas do DataFrame.
emp = dados. quadro ( nomes = c ( 'Andy' , 'Marca' , 'Bonnie' , 'Carolina' , 'John' ) ,idade = c ( vinte e um , 23 , 29 , 25 , 32 ) ,
salário = c ( 2000 , 1000 , 1500 , 3000 , 2500 ) )
gato ( ' \n \n Dataframe classificado por nomes em ordem crescente \n ' )
classificado_asc = emp [ com ( emp , ordem ( nomes ) ) , ]
imprimir ( classificado_asc )
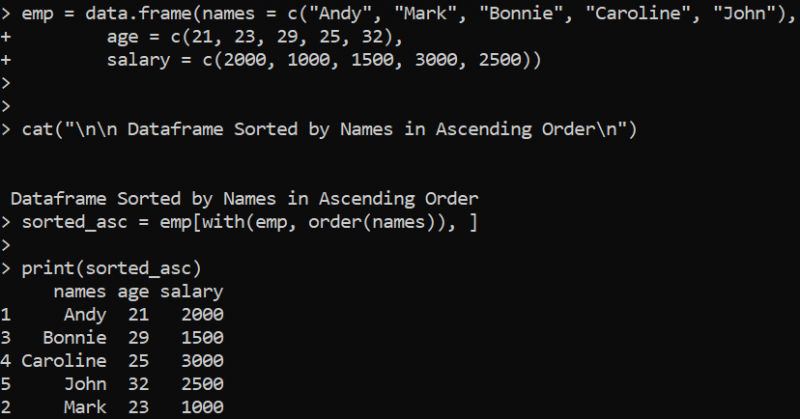
Aqui, definimos o DataFrame “emp” com três colunas contendo valores diferentes. A função cat() é implantada para imprimir a instrução para indicar que o DataFrame “emp” pela coluna “names” em ordem crescente será classificado. Para isso, utilizamos a função order() no R que retorna as posições dos índices dos valores em um vetor que está ordenado em ordem crescente. Nesse caso, a função with() especifica que a coluna “nomes” deve ser classificada. O DataFrame classificado é armazenado na variável “sorted_asc” que é passada como um argumento na função print() para imprimir os resultados classificados.
Portanto, os resultados classificados do DataFrame pela coluna “nomes” em ordem crescente são exibidos a seguir. Para obter a operação de classificação em ordem decrescente, podemos apenas especificar o sinal negativo com o nome da coluna na função order() anterior:
Exemplo 2: Classificando o DataFrame usando os parâmetros do método Order() em R
Além disso, a função order() usa os argumentos decrescentes para classificar o DataFrame. No exemplo a seguir, especificamos a função order() com o argumento para classificar em ordem crescente ou decrescente:
df = dados. quadro (
eu ia = c ( 1 , 3 , 4 , 5 , 2 ) ,
curso = c ( 'Pitão' , 'Java' , 'C++' , 'MongoDB' , 'R' ) )
imprimir ( 'Classificado em ordem decrescente por ID' )
imprimir ( df [ ordem ( df$id , diminuindo = verdadeiro ) , ] )
Aqui, primeiro declaramos a variável “df” onde a função data.frame() é definida com três colunas diferentes. Em seguida, utilizamos a função print() onde imprimimos uma mensagem para indicar que o DataFrame vai ser ordenado em ordem decrescente com base na coluna “id”. Depois disso, implantamos a função print() novamente para conduzir a operação de classificação e imprimir esses resultados. Dentro da função print(), chamamos a função “order” para classificar o DataFrame “df” com base na coluna “course”. O argumento “decrescente” é definido como TRUE para classificar em ordem decrescente.
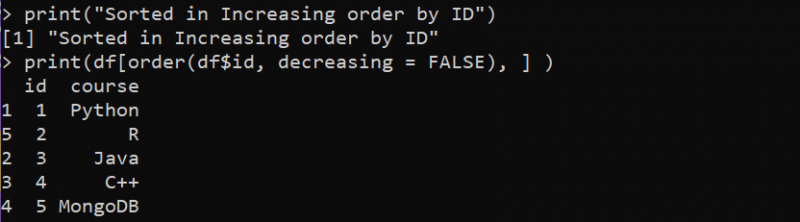
Na ilustração a seguir, a coluna “id” do DataFrame está organizada em ordem decrescente:

No entanto, para obter os resultados da classificação em ordem crescente, devemos definir o argumento decrescente da função order() com FALSE, conforme mostrado a seguir:
imprimir ( 'Classificado em ordem crescente por ID' )imprimir ( df [ ordem ( df$id , diminuindo = FALSO ) , ] )
Lá, obtemos a saída da operação de classificação do DataFrame pela coluna “id” em ordem crescente.
Exemplo 3: Classificando o DataFrame usando o método Arrange() em R
Além disso, também podemos usar o método organize() para classificar um DataFrame por colunas. Também podemos classificar em ordem crescente ou decrescente. O código R fornecido a seguir usa a função de arranjo():
biblioteca ( 'dplyr' )estudante = dados. quadro (
Eu ia = c ( 3 , 5 , 2 , 4 , 1 ) ,
marcas = c ( 70 , 90 , 75 , 88 , 92 ) )
imprimir ( 'Aumento da Ordenação por Id' )
imprimir ( arranjo ( estudante , Eu ia ) )
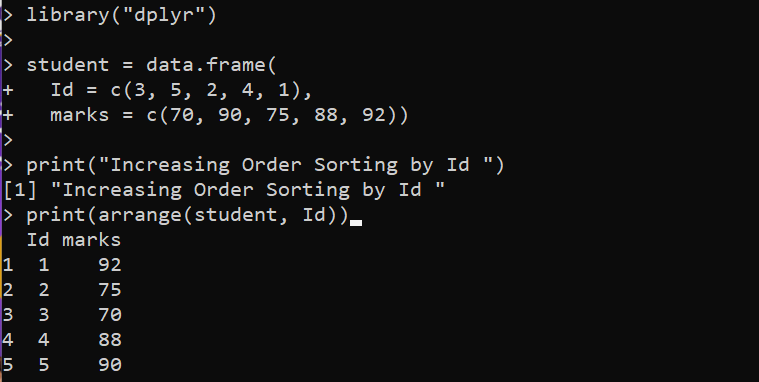
Aqui, carregamos o pacote “dplyr” do R para acessar o método organize() para ordenação. Em seguida, temos a função data.frame() que contém duas colunas e configura o DataFrame na variável “student”. Em seguida, implantamos a função organize() do pacote “dplyr” na função print() para classificar o DataFrame fornecido. A função organize() leva o DataFrame “student” como seu primeiro argumento, seguido pelo “Id” das colunas pelas quais classificar. A função print() no final imprime o DataFrame classificado no console.
Podemos ver onde a coluna “Id” é classificada em uma sequência na seguinte saída:
Exemplo 4: Classificando o DataFrame por Data em R
O DataFrame em R também pode ser classificado pelos valores de data. Para isso, a função ordenada deve ser especificada com a função as.date() para formatar as datas.
data do evento = dados. quadro ( evento = c ( '3/4/2023' , '2/2/2023' ,'10/1/2023' , '29/03/2023' ) ,
cobranças = c ( 3100 , 2200 , 1000 , 2900 ) )
data do evento [ ordem ( como . Data ( evento_data$evento , formatar = '%d/%m/%Y' ) ) , ]
Aqui, temos um DataFrame “event_date” que contém a coluna “event” com as strings de data no formato “mês/dia/ano”. Precisamos classificar essas strings de data em ordem crescente. Usamos a função order() que classifica o DataFrame pela coluna “evento” em ordem crescente. Conseguimos isso convertendo as strings de data na coluna “evento” para as datas reais usando a função “as.Date” e especificando o formato das strings de data usando o parâmetro “format”.
Assim, representamos os dados que estão ordenados pela coluna de data “evento” em ordem crescente.

Exemplo 5: Classificando o DataFrame usando o método Setorder() em R
Da mesma forma, o setorder() também é outro método para classificar o DataFrame. Ele classifica o DataFrame usando o argumento exatamente como o método organize(). O código R para o método setorder() é dado a seguir:
biblioteca ( 'Tabela de dados' )d1 = dados. quadro ( ID do pedido = c ( 1 , 4 , 2 , 5 , 3 ) ,
item de pedido = c ( 'maçã' , 'laranja' , 'kiwi' , 'manga' , 'banana' ) )
imprimir ( definir ordem ( d1 , item de pedido ) )
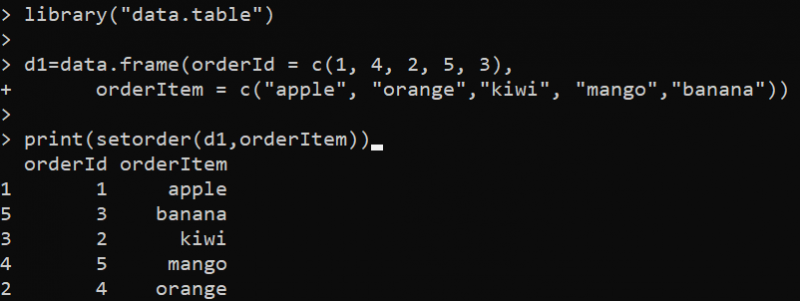
Aqui, definimos a biblioteca data.table primeiro, já que setorder() é a função deste pacote. Em seguida, empregamos a função data.frame() para criar o DataFrame. O DataFrame é especificado com apenas duas colunas que usamos para classificar. Depois disso, definimos a função setorder() dentro da função print(). A função setorder() toma o DataFrame “d1” como primeiro parâmetro e a coluna “orderId” como o segundo parâmetro pelo qual o DataFrame é classificado. A função “setorder” reorganiza as linhas da tabela de dados em ordem crescente com base nos valores da coluna “orderId”.
O DataFrame classificado é a saída no seguinte console do R:
Exemplo 6: Classificando o DataFrame usando o método Row.Names() em R
O método row.names() também é uma maneira de classificar o DataFrame em R. O método row.names() classifica os DataFrames pela linha especificada.
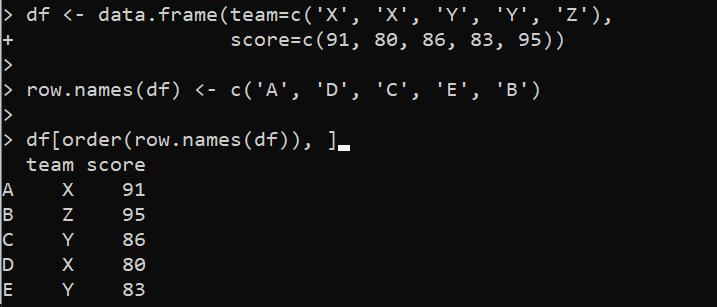
df < - dados. quadro ( equipe = c ( 'X' , 'X' , 'E' , 'E' , 'COM' ) ,pontuação = c ( 91 , 80 , 86 , 83 , 95 ) )
linha. nomes ( df ) < -c ( 'A' , 'D' , 'C' , 'E' , 'B' )
df [ ordem ( linha. nomes ( df ) ) , ]
Aqui, a função data.frame() é estabelecida dentro da variável “df” onde as colunas são especificadas com os valores. Em seguida, os nomes das linhas do DataFrame são especificados usando a função row.names(). Depois disso, chamamos a função order() para classificar o DataFrame por nomes de linha. A função order() retorna os índices das linhas classificadas que são usadas para reorganizar as linhas do DataFrame.
A saída mostra o DataFrame classificado por linhas em ordem alfabética:
Conclusão
Vimos as diferentes funções para classificar os DataFrames em R. Cada um dos métodos tem uma vantagem e precisa da operação de classificação. Pode haver mais métodos ou maneiras de classificar o DataFrame na linguagem R, mas os métodos order (), organize () e setorder () são os mais importantes e fáceis de usar para classificação.