O gerenciamento de quantidades volumosas de dados pode ser uma tarefa árdua para os gerentes de dados, principalmente se a consulta ou os resultados da verificação abrangerem várias páginas. A paginação no DynamoDB permite que o banco de dados manipule grandes quantidades de dados dividindo os resultados em várias páginas gerenciáveis. Este artigo explica a paginação do DynamoDB e fornece vários casos de uso e exemplos possíveis. Ele também destaca como a paginação no DynamoDB difere da paginação em outros bancos de dados.
O que é paginação no DynamoDB?
Geralmente, a paginação, derivada da palavra páginas, é uma técnica usada pelos bancos de dados para dividir os registros de dados em vários blocos, segmentos ou páginas. E como o AWS DynamoDB oferece suporte ao armazenamento de grandes quantidades de dados, ele apresenta recursos de paginação confiáveis.
O componente de paginação do DynamoDB garante que você só possa recuperar até 1 GB de dados por verificação ou consulta. Embora seja uma configuração padrão, você pode adicionar um parâmetro de limite em uma consulta para especificar um limite. Você também pode definir um limite para o número de registros em cada consulta de verificação.
Notavelmente, existem algumas diferenças entre a paginação no DynamoDB e a paginação em um banco de dados SQL típico. Obviamente, cada registro paginado recuperado no DynamoDB vem com um custo direto, tornando essa uma regra não escrita ao usar a paginação no DynamoDB. Esse recurso torna a paginação um fator vital para limitar os registros recuperados e os custos diretos.
Como usar a paginação no DynamoDB
1. Paginação durante uma operação de consulta
No DynamoDB, uma consulta retorna apenas os resultados de até 1 MB. Mas você pode efetivamente confirmar se há mais resultados examinando seus resultados. Notavelmente, um resultado de operação de consulta de baixo nível contém um elemento LastEvaluatedKey que não é nulo para indicar que há mais itens relacionados à sua consulta que você deve recuperar.
Um resultado sem um elemento LastEvaluatedKey que não seja nulo implica que todos os itens que correspondem à consulta cabem no limite de 1 MB e não há mais itens para recuperação. Claro, você também pode definir um limite para o número de itens por resultado. Veja o seguinte exemplo de comando:
consulta aws dynamodb \
--table-name MyTableName \
--expressão-chave-condição 'PartitionKey = :pk \
--expression-attribute-values '{' :pk ':{' S ':' a1234b '}},
--limite 10 \
Você pode usar o comando anterior para consultar sua tabela para os itens com os mesmos valores de expressão de condição chave. Vamos pesquisar nossa tabela “Pedidos” para order_Ids de Darry Tech. Também definimos um limite de 10 itens por página. Outra opção para o parâmetro –limit é usar o parâmetro –page-size para o mesmo propósito.
A paginação é uma operação automática na AWS CLI para itens abaixo de 1 MB de dados. Você pode adicionar uma chave de início exclusiva ao comando se quiser que sua consulta comece a partir de um pedido específico.
A resposta se parece com isso:
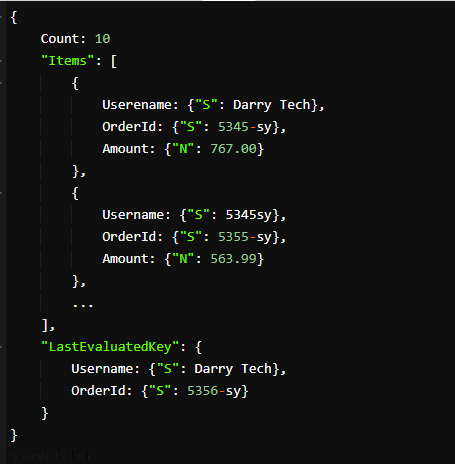
Os resultados fornecidos mostram 10 Darry Tech na primeira página. Você pode usar os valores de LastEvaluatedKey para obter mais pedidos que correspondam aos valores de chave de expressão de sua pesquisa para construir uma nova consulta. A nova solicitação de consulta contém os valores LastEvaluatedKey no parâmetro ExclusiveStartKey.
Um exemplo da sintaxe é mostrado a seguir:
consulta aws dynamodb \--table-name Tabela de Exemplo \
--expressão-chave-condição 'PartitionKey = :pk \
--expression-attribute-values '{' :pk ':{' S ':Darry Tech' \
--limite 10 \
--exclusive-start-key '{' PartitionKey ':{' S ':Darry Tech' }, 'SortKey' :{ 'S' : '5356' }} '
O comando anterior produz os próximos pedidos de compensação na próxima página, começando com o ID do pedido que possui a chave primária especificada, ou seja, {“PartitionKey”:{“S”: Darry Tech”},”SortKey”:{“S”: ”5356-sy”}}.
2. Paginação durante as operações de digitalização
Também é possível usar a paginação para operações de digitalização. Tudo funciona da mesma forma que com os comandos de consulta. No entanto, você precisa usar o atributo filter-expression. O comando se parece com o que temos aqui:
aws dynamodb scan \--table-name MinhaTabela \
--filter-expressão 'Nome do atributo =: valor' \
--expressão-atributo-valores '{':value':{'S':'ABC123'}}' \
--limite vinte \
--exclusive-start-key '{'PartitionKey':{'S':'ABC123'},'SortKey':{'S':'XYZ987'}}'
O comando anterior remove até 20 itens por página da tabela MyTable, começando pelo item cuja chave primária é {“PartitionKey”: “ABC123”, “SortKey”: “XYZ987”}. Ele filtra os resultados para incluir apenas os itens em que o atributo AttributeName possui o valor “ABC123”.
Na resposta, o LastEvaluatedKey O campo contém a chave primária do último item no conjunto de resultados. Você pode usar esse valor como o ExclusiveStartKey em um subsequente Varredura operação para recuperar a próxima página de resultados.
Conclusão
A paginação no DynamoDB melhora a capacidade de gerenciamento dos dados. No entanto, é vital saber se seus sistemas se beneficiarão da paginação. É necessário usar a paginação se você tiver uma longa lista de itens em um aplicativo. Embora a ilustração fornecida se concentre na chamada da AWS CLI, você também pode usar a paginação com SDKs da AWS, como Boto3 do Python ou qualquer SDK de sua preferência.