Neste artigo, vamos explorar a importância de estruturas de dados , os diferentes tipos de estruturas de dados disponíveis em C++ e como usá-los efetivamente em seus programas.
O que é estrutura de dados em C++
O estrutura de dados é um conceito essencial na programação e desempenha um papel vital no armazenamento e organização de dados. Em C++, uma estrutura de dados pode ser definida como uma forma de armazenar dados e gerenciá-los em um formato específico. Isso permite acesso e manipulação eficientes dos dados, tornando mais fácil para os programadores escrever e manter o código.
Em C++, o estruturas de dados possuem a seguinte sintaxe:
estrutura nome_da_estrutura {
tipo de dados1 nome1 ;
tipo de dados2 nome2 ;
datatype3 name3 ;
datatype4 name4 ;
..
..
..
} obj_name ;
Na sintaxe acima, o palavra-chave struct é usado para definir a estrutura e nome_da_estrutura é o nome da estrutura definido pelo usuário e pode variar. O datatype1 é o tipo de dados do membro da estrutura e nome1 é o nome do membro da estrutura e obj_name é o nome do objeto para o qual a estrutura é definida.
Exemplo
No exemplo abaixo, o informação da estrutura é composto por três membros: nome idade, e cidadania.
estrutura Informações
{
Caracteres nome [ cinquenta ] ;
int cidadania ;
int idade ;
}
Vamos executar este código em C++, definimos todos esses membros na estrutura pessoa e não alocamos nenhum espaço. Na função principal, inicializamos esses membros com valores específicos e os imprimimos:
#includeusando namespace std ;
estrutura Informações
{
nome da string ;
int idade ;
} ;
int principal ( vazio ) {
estrutura Informações p ;
pág. nome = 'Zainab' ;
pág. idade = 23 ;
cout << 'Nome da pessoa: ' << pág. nome << fim ;
cout << 'Idade da pessoa: ' << pág. idade << fim ;
retornar 0 ;
}
O código define uma estrutura chamada Informações com dois atributos: nome e idade. Na função principal, um novo Informações objeto é criado e seu nome e idade são atribuídos. Por fim, os valores desses campos são impressos no console usando cout.
Classificação da Estrutura de Dados em C++
Em C++ o estrutura de dados divide-se em duas grandes categorias: Estruturas de dados lineares e não lineares . As estruturas de dados são divididas com base nas seguintes características:
| Característica | Explicação | Exemplo |
| Linear | Os dados são organizados em sequência linear | Matrizes |
| Não linear | Os itens dos dados não estão na sequência linear | gráfico, árvore |
| Estático | A localização, tamanho e memória são fixos | Matrizes |
| Dinâmico | O tamanho muda dependendo da execução do programa | lista encadeada |
| homogêneo | Os itens são do mesmo tipo | Matrizes |
| Não homogêneo | Os itens podem ou não ser do mesmo tipo | Estruturas |
As categorias de estruturas de dados em C++ são:
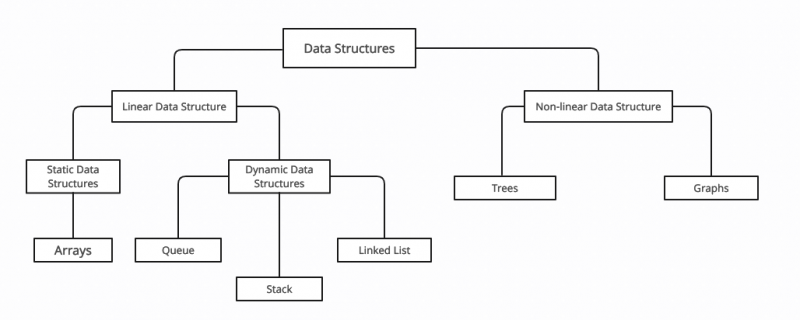
1: Matrizes
Arrays são as estruturas de dados mais fundamentais do C++. A matriz é o grupo de elementos com o mesmo tipo de dados. As matrizes facilitam a execução das operações em todo o conjunto de dados. Os valores armazenados nas matrizes são conhecidos como elementos.
2: Lista encadeada
Os elementos dos dados na lista vinculada são conectados por meio de nós. Cada nó tem o endereço e os dados do nó depois dele. Eles são melhores para adicionar e excluir nós. As listas encadeadas têm dois tipos, uma é única e a outra é lista duplamente encadeada. Em uma lista encadeada individualmente, o nó anterior possui os dados do nó seguinte, mas o próximo nó não está ciente do nó anterior. Na lista duplamente encadeada, a direção é tanto para frente quanto para trás.
3: Pilhas
Stacks é o tipo de dado abstrato que segue o princípio LIFO (Last in First Out). Esta regra significa que o último elemento inserido será excluído primeiro. Eles são usados com algoritmos de retrocesso recursivos.
4: Caudas
As filas também são do tipo abstrato de dados e seguem a regra FIFO (primeiro a entrar e primeiro a sair). Esta regra significa que o elemento inserido primeiro será excluído primeiro. Eles são úteis ao lidar com interpretações do sistema em tempo real.
5: Árvores
As árvores são um conjunto de estruturas de dados não lineares com vários nós. Permite apenas uma aresta com dois vértices.
6: Gráficos
Em um gráfico, cada nó é um vértice e cada vértice está ligado a outro vértice através de uma aresta. As esferas são vértices e as setas são arestas, são usadas para implementar cenários da vida real ou redes neurais. Os grafos têm três tipos diferentes: grafo não direcionado, grafo bidirecional e grafo ponderado.
Operações realizadas em estruturas de dados
Podemos executar as seguintes funções em estruturas de dados em C++:
- Inserção de novos elementos de dados nas estruturas de dados.
- Remoção de elementos de dados existentes da estrutura de dados.
- Exiba todos os elementos de dados na estrutura de dados.
- Procure o elemento específico na estrutura de dados.
- Organize todos os elementos em ordem crescente ou decrescente.
- Combine elementos de duas estruturas de dados e crie a nova.
Conclusão
As estruturas de dados em C++ são a maneira de manipular os dados de forma eficiente para que possam ser acessados. É importante escolher a estrutura de dados apropriada para o seu projeto, se você quiser adicionar os dados sequencialmente, vá para arrays. Compreender o conceito de estrutura de dados ajudará você a dominar a arte da programação e do design de algoritmos.