O Elasticsearch é uma solução robusta e popular para armazenar dados volumosos, não estruturados e semiestruturais. É puramente um banco de dados NoSQL e usa uma abordagem totalmente diferente para armazenar, gerenciar e recuperar dados. Ele armazena dados em um documento no formato JSON e usa APIs rest para executar diferentes operações nos dados armazenados.
Neste blog, vamos demonstrar:
- Como o Elasticsearch funciona para armazenar e pesquisar dados?
- O que são documentos do Elasticsearch?
- Como armazenar dados em um documento do Elasticsearch?
Como o Elasticsearch funciona para armazenar e pesquisar dados?
Os principais componentes ou hierarquia do Elasticsearch usados para armazenar dados estão listados abaixo:
- Documento: O documento é a parte principal do Elasticsearch que armazena dados no formato JSON. Como
- Índices: Índices são referidos como índices. É uma coleção de documentos. Como no SQL, é referido como um banco de dados.
- Índices invertidos: Suporta pesquisa de texto completo muito rápida. Ele armazena a palavra como índice e o nome do documento como referência.
O que são documentos do Elasticsearch?
O documento Elasticsearch é uma unidade de armazenamento de dados no formato JSON. Como nos bancos de dados relacionais, o documento pode ser referido como uma tabela ou uma linha de um banco de dados armazenado em algum índice. O índice pode ter vários documentos e é referido como um banco de dados que possui várias tabelas. Geralmente armazena uma estrutura de dados complexa e esteriliza os dados no formato JSON.
Além disso, cada documento pode conter vários campos que são “ valor chave ” pares para armazenar os dados, assim como uma tabela tem várias colunas ou campos em um banco de dados relacional. Então, esses pares chave-valor devem ser indexados de forma a determinar o mapeamento do documento. O mapeamento então define o tipo de dados do documento de acordo com os dados do campo, como texto, ponto flutuante, ponto geográfico, hora e muito mais.
O Elasticsearch nunca nos obrigou a pré-definir a estrutura do campo do índice e os documentos podem ter uma estrutura de campo diferente em um índice. No entanto, se o mapeamento do campo for definido para um tipo de dados específico, todos os documentos do Elasticsearch em um índice deverão seguir o mesmo tipo de mapeamento. Para verificar o funcionamento do documento para armazenar dados no Elasticsearch, vá até a próxima seção.
Como armazenar dados em um documento do Elasticsearch?
Para armazenar dados no Elasticsearch, o usuário primeiro precisa criar um índice. Em seguida, especifique os campos para armazenar os dados no documento Elasticsearch. Para a demonstração, siga as etapas listadas.
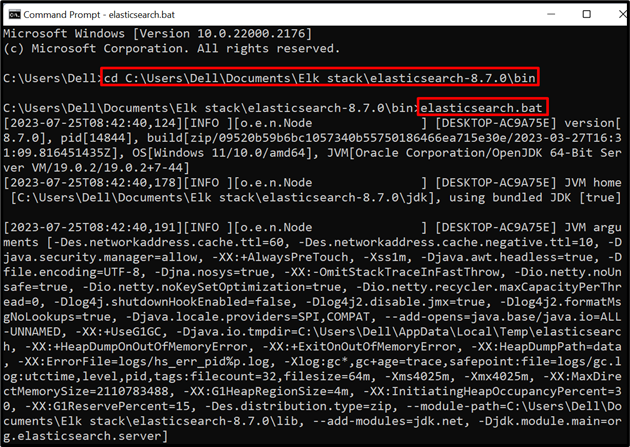
Passo 1: Inicie o Elasticsearch
Para executar o banco de dados ou mecanismo do Elasticsearch no sistema, inicie o terminal do sistema, como o prompt de comando. Depois disso, visite o “ lixeira ” pasta do Elasticsearch através da pasta “ cd ” comando:
cd C:\Users\Dell\Documents\Elk stack\elasticsearch-8.7.0\bin
Após isso, execute o arquivo batch do Elasticsearch para rodar o banco de dados no sistema:
elasticsearch.bat
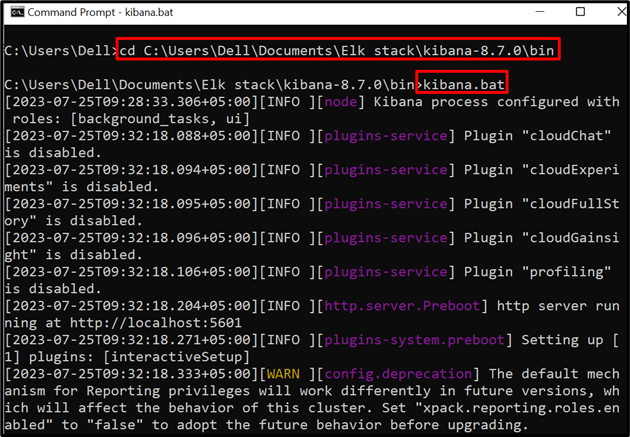
Passo 2: Inicie o Kibana
Em seguida, execute o Kibana no sistema. Para tal, visite o seu “ lixeira ” pasta do prompt de comando:
cd C:\Users\Dell\Documents\Elk stack\kibana-8.7.0\bin
Em seguida, execute o comando abaixo para iniciar a execução do Kibana:
kibana.bat
Observação: Caso você não tenha instalado e configurado o Elasticsearch e o Kibana no sistema, navegue até nossos posts e confira o passo a passo para instalá-los no sistema.
Para Elasticsearch, visite nosso “ Instalar e configurar o Elasticsearch com .zip no Windows ' artigo. Para configurar o Kibana no Windows, siga o “ Configurar o Kibana para Elasticsearch ' artigo.
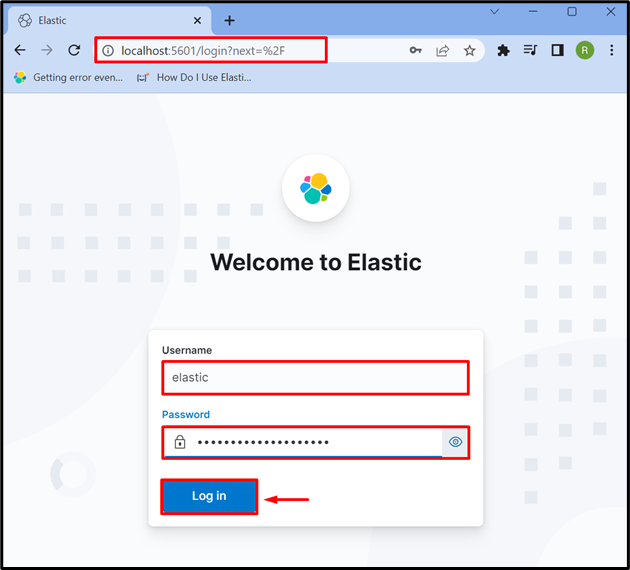
Etapa 3: faça login no Kibana
Após iniciar o Kibana no sistema, navegue até o endereço padrão do Kibana “ localhost:5601 ” no navegador e forneça as credenciais de login do Elasticsearch, como “ elástico ” usuário e senha. Depois disso, aperte o botão “ Conecte-se ' botão:
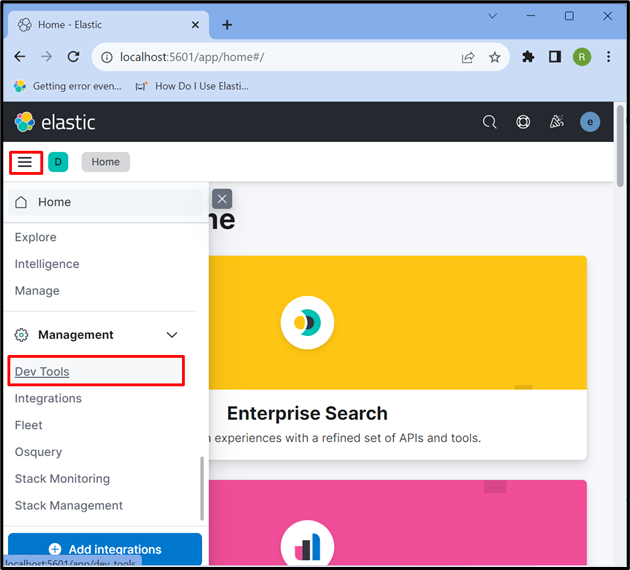
Etapa 4: abra a “ferramenta de desenvolvimento” do Kibana
Depois disso, clique no botão “ Três barras horizontais ” ícone e abra o Kibana “ ferramenta de desenvolvimento ” para usar APIs para armazenar, recuperar e atualizar os dados:
Etapa 5: criar índice
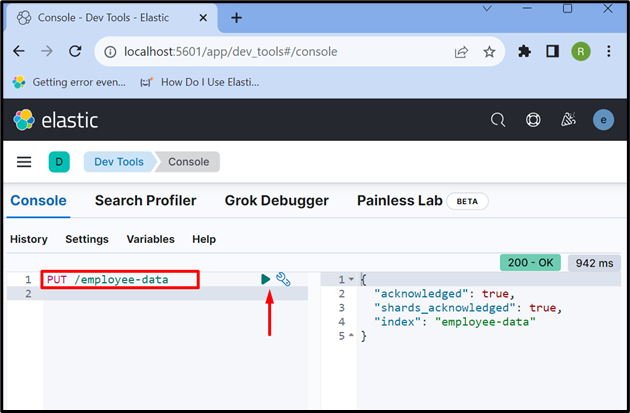
Agora, crie um novo índice usando “ PUT /
A saída mostra que o “ dados do funcionário ” o índice foi criado com sucesso:
Etapa 6: inserir dados no documento
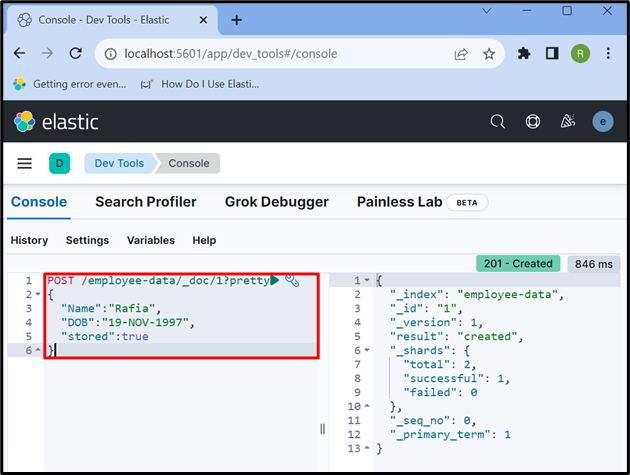
Agora, use o “ PUBLICAR ” API para armazenar os dados no índice. Na solicitação abaixo, “ dados do funcionário ” é um índice do Elasticsearch, “ _doc ” é usado para armazenar dados no documento Elasticsearch e “ 1 ” é o id:
PUBLICAR / dados do funcionário / _doc / 1 ?bonito{
'Nome' : 'Ráfia' ,
'DOB' : '19-NOV-1997' ,
'armazenado' :verdadeiro
}
Etapa 7: recuperar dados do documento do Elasticsearch
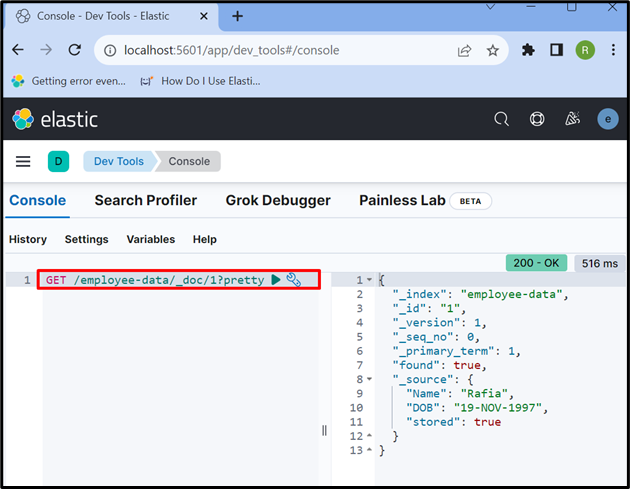
Para acessar os dados do índice ou documento do Elasticsearch, utilize o botão “ PEGAR ” API conforme usado abaixo:
PEGAR / dados do funcionário / _doc / 1 ?bonito
A saída mostra que extraímos com sucesso os dados do documento Elasticsearch com id “ 1 ”:
Isso é tudo sobre o Elasticsearch Document.
Conclusão
O documento Elasticsearch geralmente é usado para armazenar dados no formato JSON. Como nos bancos de dados relacionais, o documento pode ser referido como uma linha armazenada em algum índice. Esses índices podem ter vários documentos, assim como os bancos de dados têm tabelas diferentes. Esses documentos contêm vários campos que são “ valor chave ” pares para armazenar os dados. Este artigo demonstrou o que são documentos do Elasticsearch e como eles funcionam no Elasticsearch.