
Veremos a execução prática desta função neste tutorial.
Exemplo 1: utilizando o método Pandas Series.Reset_Index() para redefinir o índice de uma série para manter a lista de índice inicial como uma coluna
O método “Series.reset_index()” é empregado nesta ilustração para redefinir o índice de uma série Pandas e manter as alterações na cópia da série.
O funcionamento do programa Python começou por encontrar uma ferramenta adequada para o nosso sistema cumprir o script. A ferramenta “Spyder” é escolhida para a execução dos programas.
Inicializamos o script carregando primeiro as bibliotecas essenciais. Como o método “Series.reset_index()” é empregado do kit de ferramentas Pandas, necessariamente precisamos carregá-lo em nosso ambiente Python. A biblioteca Pandas é importada escrevendo o script “import pandas as pd”. A seção “as pd” nesta linha refere-se a tornar o “pd” um alias da biblioteca “Pandas”. Portanto, não precisamos usar os “Pandas”. Nós apenas escrevemos “pd” para acessar qualquer recurso do Pandas.
O primeiro método que acessamos do módulo Pandas usando o alias “pd” é o método “pd.Series”. Este método é um método interno do Pandas para criar uma série com a matriz de valores fornecida. Chamamos esta função e especificamos os valores que são “34”, “21”, “18”, “45”, “76”, “82”, “22”, “40”, “91”, “101”, e “8”. Além disso, o nome da coluna é definido usando o parâmetro “name” como “Data”.
Depois disso, inicializamos uma variável “new_index” e atribuímos alguns valores a ela, mas com o mesmo comprimento que usamos para os valores da série. Os valores para a variável “new_index” são “A01”, “A02”, “A03”, “A04”, “A05”, “A06”, “A07”, “A08”, “A09”, “A10” e “A11”. Usamos os valores armazenados nesta variável para o índice. Para definir a coluna de índice da série, invocamos a propriedade “Series.index” e atribuímos a variável “new_index”. Os valores armazenados no “new_index” são colocados como o índice da série em vez da lista padrão do índice que começa em “0”. Por fim, para ver a série com o índice especificado, chamamos a função “print()” e passamos a série “Number” como entrada para imprimir seu conteúdo.
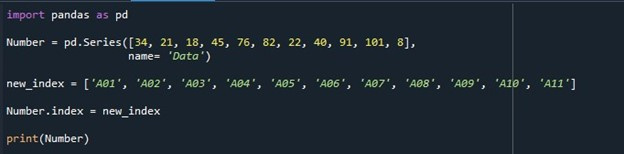
A série resultante com os índices especificados que substituíram a lista de índices padrão é exibida no terminal.
Para redefinir essa lista de índices definida pelo usuário para a lista padrão, utilizamos o método Pandas “Series.reset_index()”.
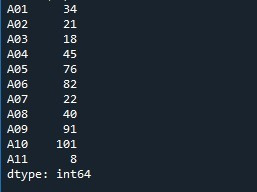
Chamamos o método “Series.reset_index()” para redefinir a lista de índices. O nome da série é fornecido como “Number” com o método “reset_index()”. Assim, ele funciona verificando a série e redefinindo a lista de índices para as configurações padrão. Para salvar essas modificações, criamos a variável “Saída” que gera uma cópia da série com uma lista de índices alterada. Empregamos a função “print()” para exibir o conteúdo de “saída”.

Na imagem de saída, podemos ver que o índice sequencial padrão é exibido. Além disso, a lista de índices especificada é adicionada como uma nova coluna da série com o rótulo “índice”.
Exemplo 2: utilizando o método Pandas Series.Reset_Index() para redefinir o índice de uma série e descartar o índice inicial
Esta instância demonstra a técnica para redefinir o índice de uma série Pandas usando o método “Series.reset_index()”. Além disso, descartamos a coluna de índice definida inicialmente usando o parâmetro “drop” da função “Series.reset_index()”.
Para a execução do trecho de código, primeiro importamos a biblioteca Pandas como “pd”. Em seguida, exercitamos um método deste módulo Pandas atualmente carregado para criar uma série Pandas. A função “pd.Series()” é empregada e fornecemos uma matriz de valores para ela para gerar uma série usando esses valores. Os valores que especificamos para a construção da série são do tipo de dados string. Esses valores são “Nestle”, “Cadbury”, “Mars”, “Dove”, “Lindt”, “Godiva”, “Ghirardelli” e “Ferrero”. Usamos o parâmetro “name” para rotular esta coluna. Chamamos de “Marca” porque criamos uma série que contém os nomes das marcas de chocolate. O comprimento da série é 8. Um objeto de série “Chocolates” é criado e atribuído o resultado produzido a partir da invocação do método Pandas “pd.Series()”.
Além disso, uma variável “identificadora” é criada e inicializada com esses valores “A”, “B”, “C”, “D”, “E”, “F”, “G” e “H”. O comprimento dos valores que ele contém é o mesmo que o comprimento dos valores da série. Agora, alteramos a lista de índices padrão da série e fornecemos os valores da variável “identificadora” a ser usada como índice. Para definir o índice, a propriedade “Series.index” é exercida. O nome da série “Chocolates” é mencionado com a propriedade “.index”. Atribuímos a variável “identificadora” à propriedade index. A propriedade “index” extrai os valores preservados na variável “identifier” e os torna a lista de índices da série. O método “print()” é finalmente invocado para imprimir a série “Chocolates”.
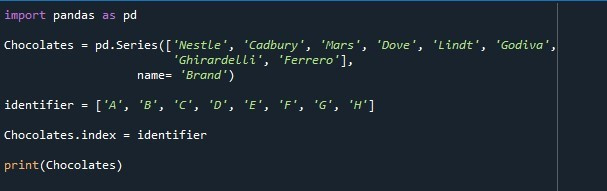
A série exibida no instantâneo a seguir mostra que colocamos com sucesso a lista de índice especificada em vez da lista de índice padrão.
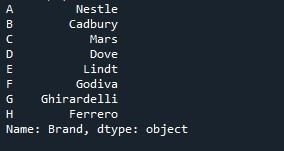
Agora, se você quiser redefinir as configurações de índice, basta usar o método Pandas “Series.reset_index()”. Fornecemos nosso nome de série com este método. Ele apenas redefine as configurações de índice para o padrão dessa série específica.
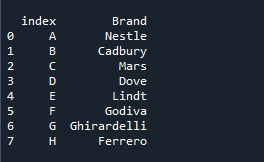
Chamamos o método “Series.reset_index()” e fornecemos o nome da série como “Chocolates”. Para armazenar a série com a lista de índices padrão, criamos uma variável “ser”. Agora, precisamos ver esta série. Para isso, é utilizado o método “print()”. Dentro de suas chaves, passamos a variável “ser” para que ela exiba o que essa variável preservou.

A série resultante é exibida com a lista de índices padrão. Mas também, a lista de índices inicialmente especificada está presente como uma coluna na série com o título “índice”. O método “reset_index()” coloca a lista de índice padrão, mas não removeu a lista especificada para o índice e a mantém como uma nova coluna.
Para descartar a lista de índices inicialmente especificada que agora é anexada como uma coluna na série, utilizamos um parâmetro no método “reset_index()”. Este parâmetro é o “drop”. Ele recebe o valor booleano como entrada. Por padrão, o valor do parâmetro “drop” é definido como “False”, o que significa que ele não descarta a lista de índices inicial. Como queremos eliminar a lista de índices inicial, temos que alterar seu valor para “True”.
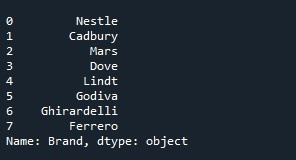
Apenas passamos o atributo “drop” com o valor “True” para a função “Series.reset_index()”.

A saída renderizada demonstra uma série que agora eliminou a coluna “índice” e é exibida com a lista de índices padrão. O resultado obtido é apresentado no instantâneo a seguir:
Conclusão
Você pode ter os conjuntos de dados em que sua lista de índices é especificada para serem usados em vez da lista de índices padrão. Talvez seja necessário redefini-lo para as configurações padrão. Por esta razão, Pandas nos fornece o método “Series.reset_index()”. Este método altera o índice para as configurações padrão. Nós fornecemos duas técnicas para utilizar este método. Para a primeira ilustração, mantivemos a lista de índices inicialmente especificada na série resultante como uma coluna após anexar a lista de índices padrão. A outra técnica demonstrou como eliminar a lista especificada da série usando o parâmetro “drop”.