“Valores separados por vírgula (CSV) é um dos formatos de dados mais versáteis e fáceis de usar. É um formato de dados leve que permite que desenvolvedores e aplicativos transfiram e analisem dados de uma fonte para outra.
Os dados CSV armazenam dados em um formato tabular onde cada coluna é separada por uma vírgula e um novo registro é alocado para uma nova linha. Isso o torna uma escolha muito boa para exportar bancos de dados, como bancos de dados SQL, dados do Cassandra e muito mais.
Portanto, não é surpresa que você encontre um cenário em que precise importar um arquivo CSV para seu banco de dados.
O objetivo deste tutorial é mostrar um método rápido e simples de importar um arquivo CSV para o cluster do Elasticsearch usando o painel do Kibana.”
Vamos pular.
Requisitos
Antes de mergulhar, certifique-se de ter os seguintes requisitos:
- Um cluster do Elasticsearch com status de integridade verde.
- Servidor Kibana conectado ao seu cluster Elasticsearch.
- Permissões suficientes para gerenciar índices em seu cluster.
Exemplo de arquivo CSV
Como de costume, o primeiro requisito é o arquivo CSV de origem. É bom garantir que os dados em seu arquivo CSV estejam bem formatados e que não contenham erros.
Para fins de ilustração, usaremos um conjunto de dados gratuito que contém filmes e programas de TV da Amazon Prime.
Abra seu navegador e navegue até o recurso abaixo:
https://www.kaggle.com/datasets/shivamb/amazon-prime-movies-and-tv-shows
Siga o procedimento para baixar o conjunto de dados para sua máquina local. Você pode extrair o arquivo baixado com o comando:
$ descompactar a~ / Transferências / arquivo.zip
Importar arquivo CSV
Depois de ter seu arquivo de origem pronto, podemos prosseguir e discutir como importá-lo.
Comece indo até o painel inicial do Kibana e selecionando a opção “carregar um arquivo”.
Localize o arquivo CSV de destino que você deseja importar na janela do iniciador.
Selecione seu arquivo de origem e clique em upload.
Permita que o Elasticsearch e o Kibana analisem o arquivo carregado. Isso analisará o arquivo CSV e determinará o formato de dados, campos, tipos de dados etc.
NOTA: Dependendo da configuração do cluster e do tamanho dos dados, esse processo pode demorar um pouco. Certifique-se de que o nó mestre esteja respondendo para evitar tempos limite.
Quando o processo estiver concluído, você deverá obter uma amostra do conteúdo do arquivo e das estatísticas do arquivo analisadas pela Elastic.
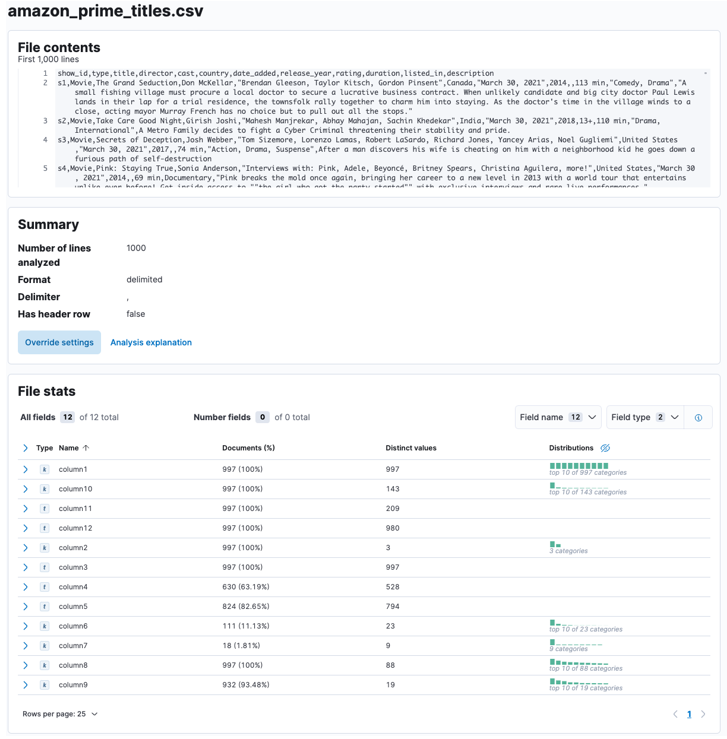
Você pode personalizar vários parâmetros, por exemplo, o delimitador, as linhas de cabeçalho etc. Por exemplo, podemos personalizar a saída acima para informar ao Elastic que nosso arquivo CSV contém arquivos de cabeçalho.
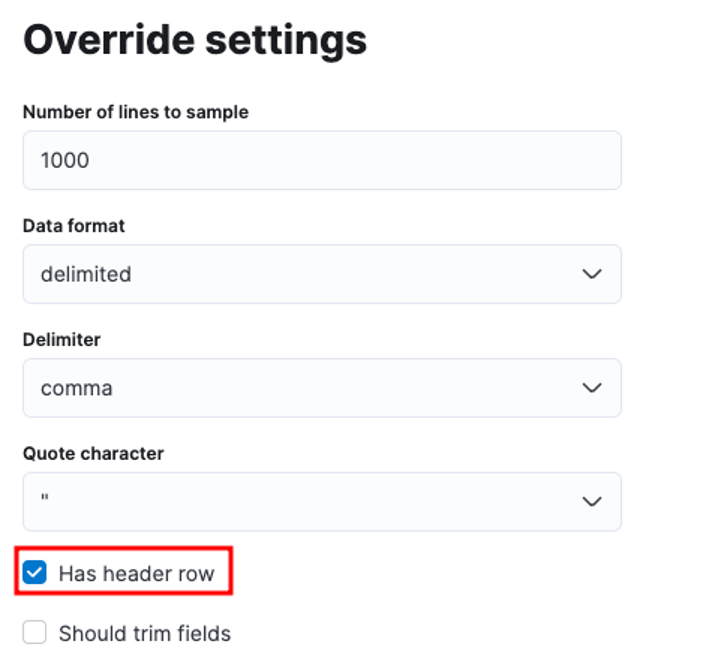
Podemos então clicar em aplicar e reanalisar os dados. Isso deve formatar os dados no formato correto, incluindo os campos.
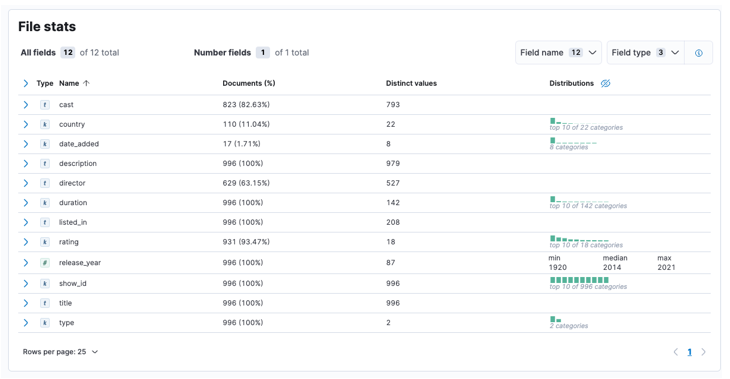
Em seguida, podemos clicar em importar para prosseguir para o painel importado.
Aqui, precisamos criar um índice no qual os dados CSV são armazenados. Você pode alocar qualquer nome compatível ao seu índice.
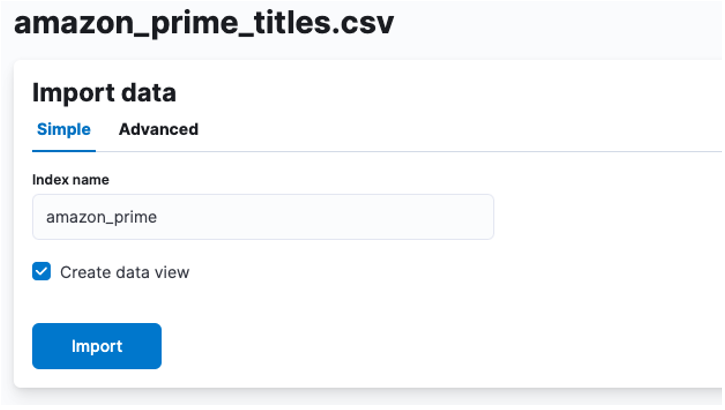
Se você deseja personalizar suas propriedades de índice, como o número de fragmentos, réplicas, mapeamentos, etc. Selecione a opção avançada e ajuste suas configurações como desejar.
Por fim, clique em importar e veja como o Kibana faz sua “mágica”. Depois de concluído, você pode acessar seu índice por meio da API Elasticsearch ou usar o painel do Kibana.
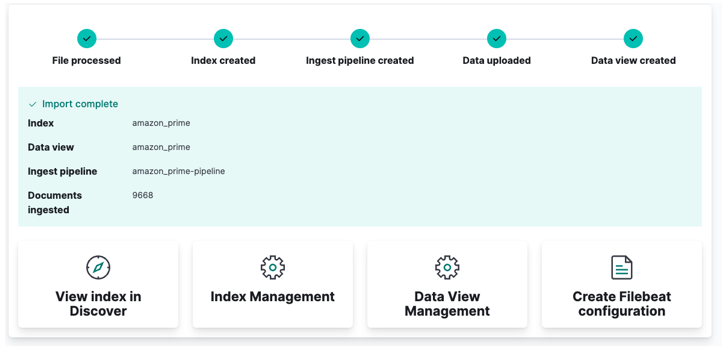
E pronto!!
Conclusão
Nesta postagem, abordamos o processo de busca e importação do conjunto de dados CSV para o cluster do Elasticsearch usando o painel do Kibana.
Obrigado por ler e codificação feliz !!