Esboço rápido
Esta postagem contém as seguintes seções:
- Como usar um agente API assíncrono em LangChain
- Método 1: usando execução serial
- Método 2: usando execução simultânea
- Conclusão
Como usar um agente API assíncrono no LangChain?
Os modelos de chat executam várias tarefas simultaneamente, como compreender a estrutura do prompt, suas complexidades, extrair informações e muito mais. Usar o agente Async API no LangChain permite ao usuário construir modelos de chat eficientes que podem responder a várias perguntas ao mesmo tempo. Para aprender o processo de uso do agente API Async em LangChain, basta seguir este guia:
Etapa 1: instalação de estruturas
Primeiro de tudo, instale o framework LangChain para obter suas dependências do gerenciador de pacotes Python:
pip instalar langchain
Depois disso, instale o módulo OpenAI para construir o modelo de linguagem como llm e configure seu ambiente:
pip instalar openai
Etapa 2: ambiente OpenAI
O próximo passo após a instalação dos módulos é montando o ambiente usando a chave API do OpenAI e API Serper para pesquisar dados do Google:
importar os
importar Obter passagem
os . aproximadamente [ 'OPENAI_API_KEY' ] = Obter passagem . Obter passagem ( 'Chave de API OpenAI:' )
os . aproximadamente [ 'SERPER_API_KEY' ] = Obter passagem . Obter passagem ( 'Chave de API Serper:' )
Passo 3: Importando Bibliotecas
Agora que o ambiente está configurado, basta importar as bibliotecas necessárias como asyncio e outras bibliotecas usando as dependências LangChain:
de cadeia longa. agentes importar agente_de_inicialização , carregar_ferramentasimportar tempo
importar assíncio
de cadeia longa. agentes importar Tipo de agente
de cadeia longa. llms importar OpenAI
de cadeia longa. retornos de chamada . saída padrão importar StdOutCallbackHandler
de cadeia longa. retornos de chamada . rastreadores importar LangChainTracer
de aiohttp importar Sessão do Cliente
Etapa 4: perguntas de configuração
Defina um conjunto de dados de perguntas contendo diversas consultas relacionadas a diferentes domínios ou tópicos que podem ser pesquisados na internet (Google):
questões = ['Quem é o vencedor do campeonato do Aberto dos EUA em 2021' ,
“Qual a idade do namorado da Olivia Wilde” ,
“Quem é o vencedor do título mundial de Fórmula 1” ,
'Quem venceu a final feminina do Aberto dos Estados Unidos em 2021' ,
'Quem é o marido de Beyoncé e qual a idade dele' ,
]
Método 1: usando execução serial
Depois de concluídas todas as etapas, basta executar as perguntas para obter todas as respostas usando a execução serial. Isso significa que uma pergunta será executada/exibida por vez e também retornará o tempo completo necessário para executar estas perguntas:
llm = OpenAI ( temperatura = 0 )ferramentas = carregar_ferramentas ( [ 'cabeçalho do Google' , 'llm-matemática' ] , llm = llm )
agente = agente_de_inicialização (
ferramentas , llm , agente = Tipo de agente. ZERO_SHOT_REACT_DESCRIPTION , detalhado = Verdadeiro
)
é = tempo . contador_perf ( )
#configurando contador de tempo para obter o tempo utilizado para o processo completo
para q em questões:
agente. correr ( q )
decorrido = tempo . contador_perf ( ) -s
#imprime o tempo total utilizado pelo agente para obter as respostas
imprimir ( f 'Serial executado em {elapsed:0.2f} segundos.' )
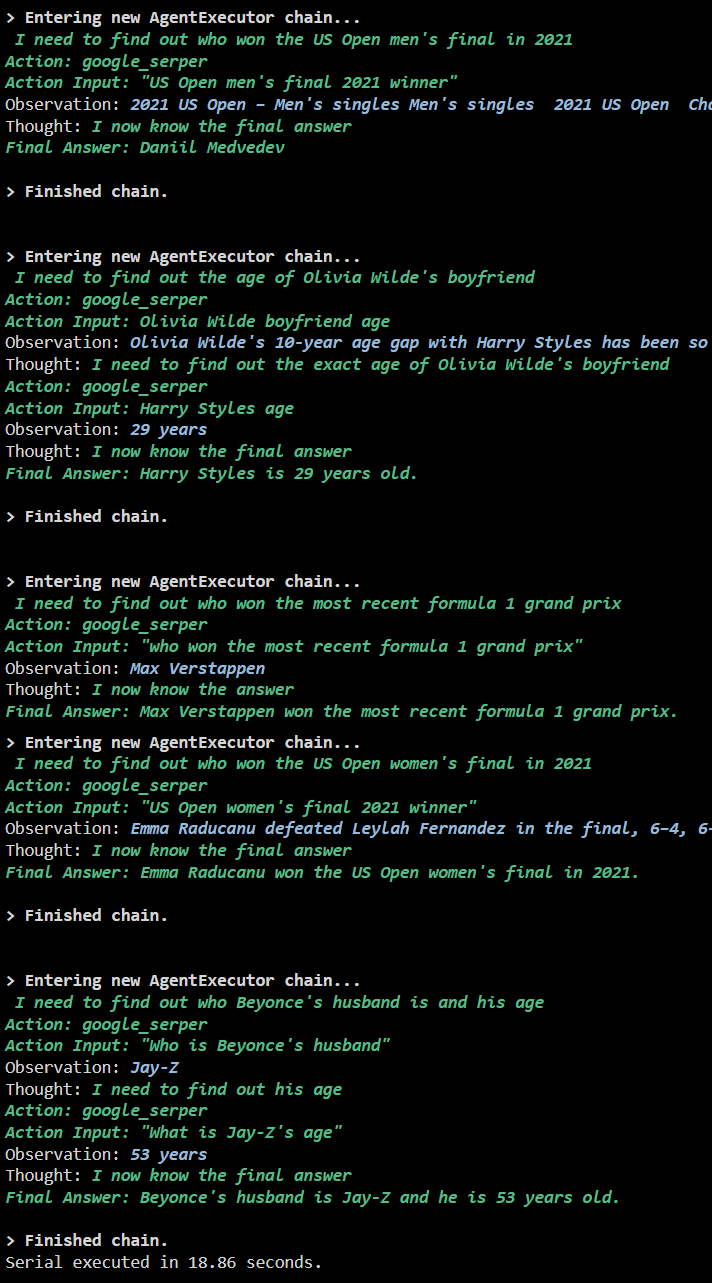
Saída
A captura de tela a seguir mostra que cada pergunta é respondida em uma cadeia separada e, assim que a primeira cadeia é concluída, a segunda cadeia se torna ativa. A execução serial leva mais tempo para obter todas as respostas individualmente:
Método 2: usando execução simultânea
O método de execução simultânea pega todas as perguntas e obtém suas respostas simultaneamente.
llm = OpenAI ( temperatura = 0 )ferramentas = carregar_ferramentas ( [ 'cabeçalho do Google' , 'llm-matemática' ] , llm = llm )
#Configurando o agente usando as ferramentas acima para obter respostas simultaneamente
agente = agente_de_inicialização (
ferramentas , llm , agente = Tipo de agente. ZERO_SHOT_REACT_DESCRIPTION , detalhado = Verdadeiro
)
#configurando contador de tempo para obter o tempo utilizado para o processo completo
é = tempo . contador_perf ( )
tarefas = [ agente. doença ( q ) para q em questões ]
aguarde assíncio. juntar ( *tarefas )
decorrido = tempo . contador_perf ( ) -s
#imprime o tempo total utilizado pelo agente para obter as respostas
imprimir ( f 'Simultâneo executado em {elapsed:0.2f} segundos' )
Saída
A execução simultânea extrai todos os dados ao mesmo tempo e leva bem menos tempo que a execução serial:
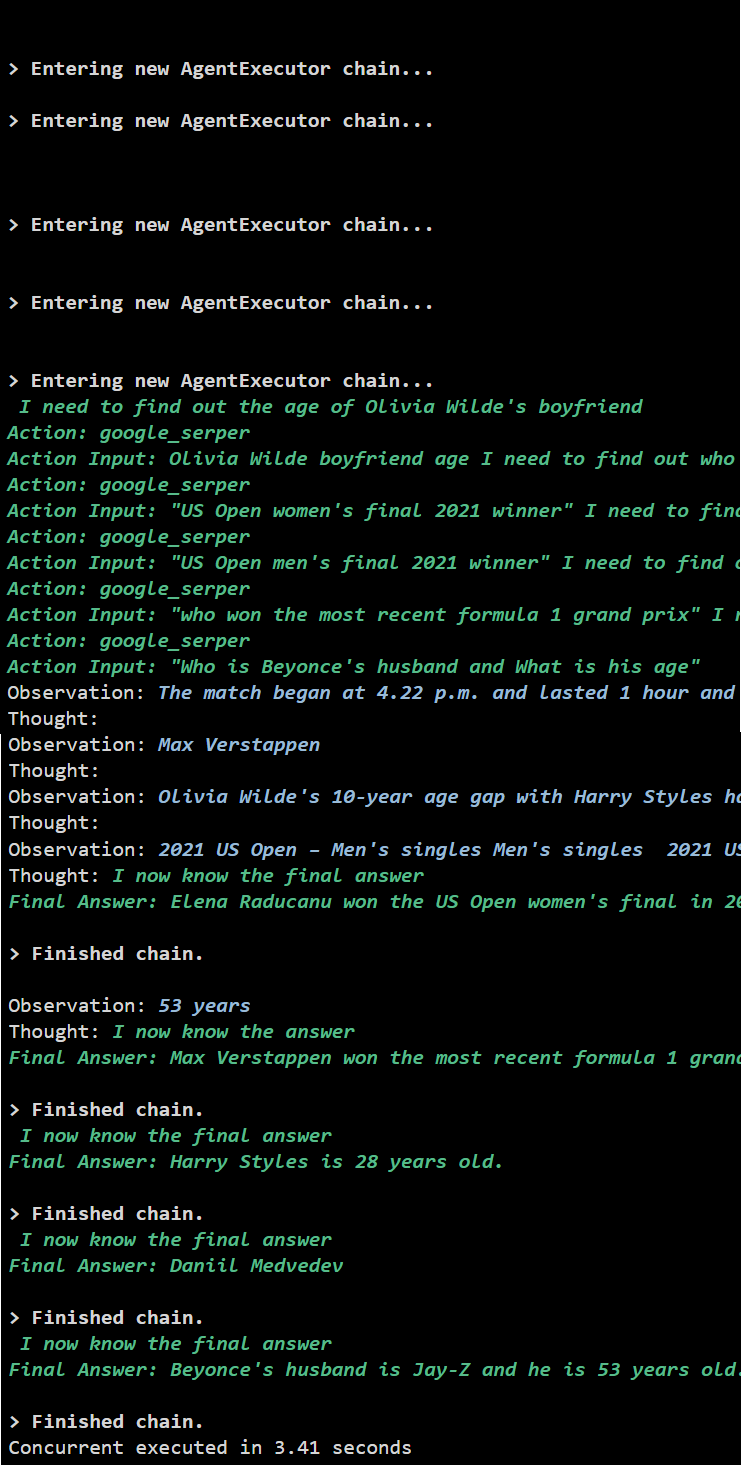
Trata-se de usar o agente Async API no LangChain.
Conclusão
Para usar o agente Async API no LangChain, basta instalar os módulos para importar as bibliotecas de suas dependências para obter a biblioteca asyncio. Depois disso, configure os ambientes usando as chaves da API OpenAI e Serper fazendo login em suas respectivas contas. Configure o conjunto de questões relacionadas aos diferentes temas e execute as cadeias de forma serial e simultânea para obter seu tempo de execução. Este guia elaborou o processo de uso do agente API Async em LangChain.