- Não substitui os dados recuperados, mas preenche as lacunas em caso de recuperação iterativa. No entanto, pode ser truncado se a ferramenta for instruída a fazê-lo explicitamente.
- Recupere dados de vários arquivos ou blocos em um único arquivo.
- Suporta vários tipos de interfaces de dispositivos, como unidades SATA, ATA, SCSI, MFM, disquetes e cartões SD.
Neste guia, explorarei esta ferramenta de recuperação de dados incrivelmente útil. Também discutirei seu processo de instalação e como usá-lo para recuperar um dispositivo de bloco ou partição.
- Instalando o ddrescue
- Compreendendo o básico
- Considerações importantes
- Usando ddrescue
- Recuperando o bloco corrompido
- Restaurando o arquivo de imagem para um novo bloco
- Recuperando bloco para outro bloco
- Recuperando dados específicos dos arquivos de imagem recuperados
- Características avançadas
- Como funciona o ddrescue
- Conclusão
Observação: Estou usando a distribuição Linux (Ubuntu 22.04) para obter as instruções deste guia. O processo de instalação do utilitário ddrescue pode ser diferente, mas as instruções serão as mesmas em todas as distribuições Linux.
Instalando o ddrescue
Para instalar o ddrescue no Linux, especialmente Ubuntu e seus sabores ou Baseado em Debian distros, use:
sudo apto instalar gddrescue
Para instalá-lo em REHL , Fedora , e CentOS , primeiro habilite o ESQUENTAR (Pacotes extras para Enterprise Linux).
sudo yum instalar liberação quente
O comando acima é para versões mais recentes da respectiva distribuição.
Em seguida, execute o seguinte comando para instalar o ddrescue:
sudo yum instalar ddrescuePara distribuições Linux baseadas em Arch, como Arch-Linux e Manjaro , use o comando fornecido abaixo para instalar o utilitário de recuperação ddrescue.
sudo pacman -S ddrescue
Como estou usando o Ubuntu 22.04, usarei o gerenciador de pacotes APT para instalá-lo.
Compreendendo o básico
Antes de usar a ferramenta ddrescue para recuperar dados, recomendo que os usuários que são novos no processo de recuperação entendam algumas convenções de nomenclatura do Linux.
O Linux reconhece blocos (dispositivos) como arquivos e os coloca no /dev diretório. Para listar os arquivos no diretório /dev, use o ls /dev comando.
O Discos rígidos (blocos de armazenamento) são representados com SD seguido por alfabetos; no caso de vários dispositivos de armazenamento, os arquivos serão representados como /dev/sd a, /dev/sd b, e assim por diante.
Se o dispositivo de armazenamento tiver partições , então eles serão representados por um número com o respectivo nome de arquivo da unidade, como /dev/sda 1 , /dev/sda 2 , e assim por diante.
Para listar todos os blocos e demais dispositivos conectados ao sistema, utilize a lista de blocos lsblk comando:
lsblk 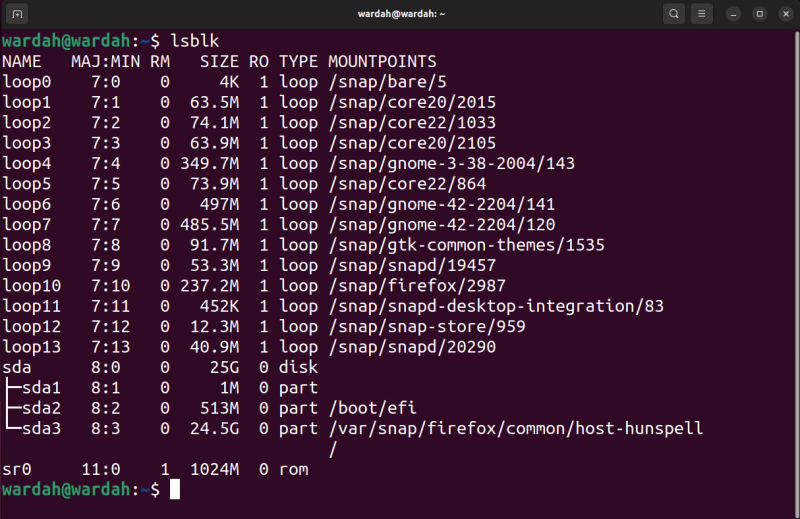
O comando ddrescue pode recuperar o bloco inteiro (contendo MBR e partições) ou também uma partição. Por outro lado, se você precisar recuperar apenas arquivos específicos de uma partição específica, é melhor recuperar a partição em vez do bloco inteiro.
Considerações importantes
Antes de usar o utilitário ddrescue, alguns pontos importantes devem ser considerados:
- Não tente recuperar um bloco montado, o bloco não deve estar no modo somente leitura.
- Não tente reparar um bloco com erros de E/S.
- O sistema pode alterar os nomes dos dispositivos de entrada e saída na reinicialização. Certifique-se de que os nomes dos dispositivos estejam corretos antes de iniciar o processo de cópia.
- Se você estiver usando um bloco separado como dispositivo de saída, todos os dados no dispositivo serão substituídos.
Usando ddrescue
Depois de instalar o utilitário ddrescue e compreender as convenções de nomenclatura, a próxima etapa é identificar o disco com falha e recuperá-lo usando a ferramenta ddrescue.
Recuperando o bloco corrompido
O primeiro exemplo abrangerá o processo de recuperação de todo o bloco. Primeiro, liste os blocos usando o lsblk comando:
lsblk -o NOME, TAMANHO, FSTYPEO -o flag é usado para especificar qual tipo de informação (campos) o comando deve gerar. Eu mencionei o NOME , TAMANHO , e FSTYPE ou tipo de sistema de arquivos.
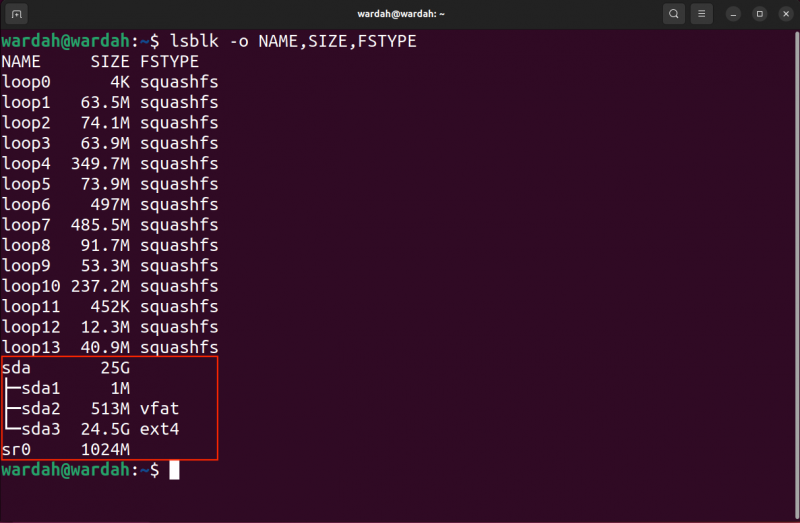
Agora, você pode identificar o bloco de destino, a partição e o local para salvar o arquivo de imagem resgatado.
Outra coisa importante a se notar é que no Linux, o nome do bloco é atribuído dinamicamente na inicialização e após a reinicialização, os nomes dos blocos podem mudar. Portanto, tenha cuidado ao anotar os nomes dos blocos.
Agora, use a seguinte sintaxe para resgatar o bloco como um arquivo de imagem com um arquivo de log no diretório raiz.
sudo ddrescue -d -rX / desenvolvedor / [ bloquear ] [ caminho / nome ] .img [ nome_do_arquivo_de_log ] .registroObservação: Substituir [bloquear] , [caminho/nome] do arquivo de imagem e [nome_do_arquivo_de_log] com os nomes preferidos em conformidade.
Neste exemplo, estou recuperando o /dev/sda no diretório raiz com o nome do arquivo de imagem recuperação.img . O arquivo de log, também conhecido como arquivo de mapa, é essencial se você quiser retomar a recuperação a qualquer momento.
sudo ddrescue -d -r2 / desenvolvedor / recuperação sda2.img recuperação.logDois sinalizadores importantes são usados no comando acima.
| d | -indireto | É usado para dizer à ferramenta para acessar diretamente o disco, ignorando o cache do kernel |
| RX | –repetir passes | É usado para dizer à ferramenta para tentar novamente o setor defeituoso X vezes |
Ao executar o comando acima, você notará dois arquivos aparecendo no navegador de arquivos com os nomes recuperação.img e recuperação.log .
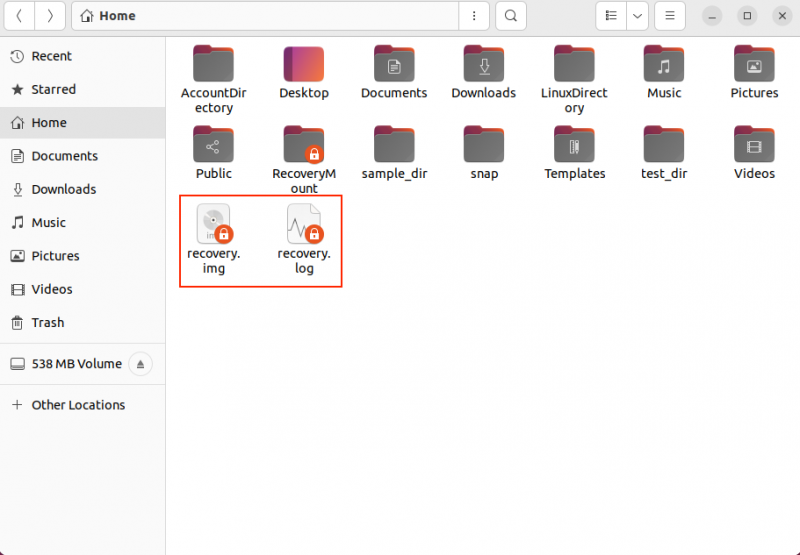
O tempo de recuperação depende do tamanho do bloco de entrada e do dano. Se você estiver recuperando um bloco grande, recomendo ter um arquivo de log, pois pode levar várias horas ou até dias para concluir o processo.
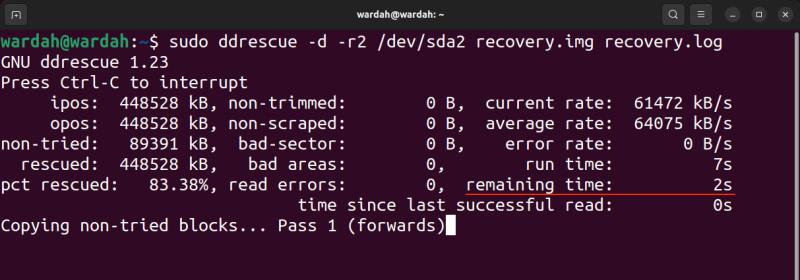
A saída do comando acima é fornecida abaixo:
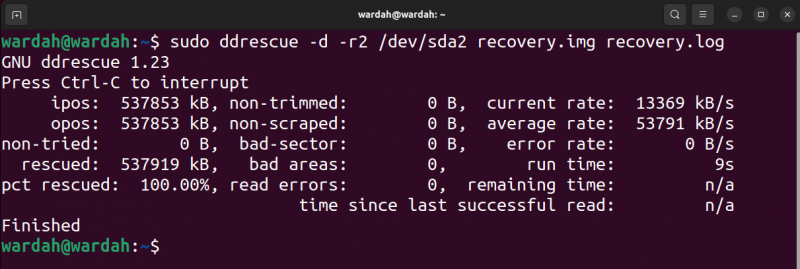
Na imagem de saída, ipos é a posição de entrada do arquivo de entrada de onde a cópia é iniciada e o úlceras é a posição de saída no arquivo de saída onde os dados estão sendo gravados.
O não tentado é o tamanho do bloco que não está pendente para ser tentado. O resgatado indica o tamanho do bloco recuperado com sucesso. O pct resgatado indica a recuperação bem-sucedida de dados em porcentagem. Os termos, não aparado , não descartado , setor ruim , e áreas ruins são autoexplicativos. No entanto, o erros de leitura termo indica as tentativas de leitura com falha em números.
O tempo de execução mostra o tempo que a ferramenta levou para concluir o processo, enquanto o tempo restante é o tempo restante para concluir o processo de recuperação. A saída acima mostra o tempo restante 0 porque o processo foi concluído, leia a saída na imagem a seguir de um processo inacabado.
Vamos ver o que obtemos no arquivo de log; para abrir o arquivo de log gerado, use o recuperação do vim.log comando.
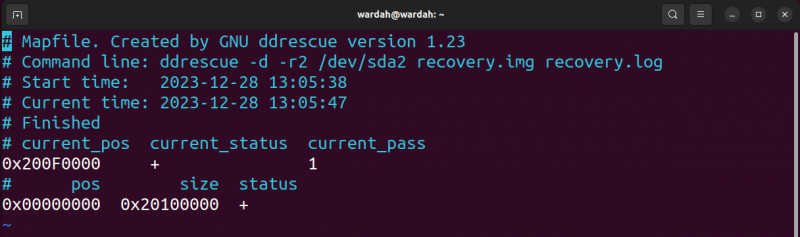
O status atual é + o que significa que o processo está concluído, enquanto o posição_atual é a posição no bloco.
Uma lista dos status atuais é fornecida na tabela a seguir:
| ? | Copiando |
| * | Aparar |
| / | Sucateamento |
| – | Tentando novamente |
| F | Preenchendo os blocos especificados |
| G | Gerando o arquivo de log |
| + | O processo está concluído |
Abaixo disso, o arquivo de log contém indicações de status dos blocos resgatados anteriormente na forma de caracteres listados abaixo:
| ? | O bloco não foi tentado |
| * | O bloco com falha não aparado |
| / | O bloco com falha não descartado |
| – | O bloco com falha do setor defeituoso |
| + | Bloco finalizado |
Restaurando o arquivo de imagem para um novo bloco
Assim que terminar o processo de recuperação e tiver o arquivo de imagem. Agora você pode querer migrar para a nova unidade a partir de uma unidade corrompida. Para mover o arquivo de imagem para um novo bloco, primeiro conecte esse bloco ao sistema e depois identifique o nome do bloco usando o lsblk comando.
Vamos supor que seja /dev/sdb , use o seguinte comando para copiar a imagem para um novo bloco.
sudo ddrescue -f recuperação.img / desenvolvedor / arquivo de log sdb.logO -f flag é usado para substituir o novo bloco se houver algum dado. Lembre-se de que o nome do arquivo de log deve ser diferente para mantê-lo separado do arquivo de log armazenado anteriormente.
A operação acima também pode ser feita usando o dd , outro comando poderoso usado para copiar os arquivos.
sudo dd se =recuperação.img de = / desenvolvedor / sdbAntes de fazer uma restauração, lembre-se que o novo bloco deve ser grande o suficiente para manter todo o bloco recuperado; por exemplo, se o bloco de recuperação for de 5 GB, o novo bloco deverá ser maior que 5 GB.
Se o arquivo de imagem recuperado apresentar muitos erros, eles poderão ser reparados usando o fsck comando no Linux até certo ponto. Enquanto estiver no Windows, você pode usar o CHKDSK ou SFC comandos para fazer isso. No entanto, a recuperação depende do número de erros gerados pelo arquivo corrompido.
Agora, o processo de recuperação e restauração está concluído. Outra coisa importante a observar é que você pode recuperar um bloco corrompido diretamente em outro bloco, em vez de criar um arquivo de imagem e copiá-lo para o novo bloco. Bem, na seção seguinte, abordarei esse processo em detalhes.
Recuperando bloco para outro bloco
Para recuperar um bloco diretamente para um novo bloco, primeiro conecte o bloco ao sistema e use novamente lsblk comando para identificar o nome do bloco. Nomes de blocos incorretos podem atrapalhar todo o processo e você pode perder dados.
Após identificar o bloco de origem e o bloco de destino, use o seguinte comando para recuperar o bloco:
sudo ddrescue -d -f -r2 / desenvolvedor / [ fonte ] / desenvolvedor / [ destino ] backup.logVamos assumir /dev/sdb é o bloco de destino, então para copiar o /dev/sda diretório para o novo bloco use:
sudo ddrescue -d -f -r2 / desenvolvedor / sda / desenvolvedor / backup sdb.logNovamente, consulte as considerações críticas mencionadas nas seções anteriores antes de tentar este processo.
Recuperando dados específicos dos arquivos de imagem recuperados
Em muitos casos, o objetivo da recuperação de dados é encontrar arquivos específicos em unidades corrompidas. Para acessar o arquivo específico você precisa montar o arquivo de imagem. No Linux, o arquivo de imagem recuperado pode ser explorado usando o montar comando.
Antes de montar o arquivo de imagem, crie uma pasta ou diretório no qual deseja extrair o conteúdo do arquivo de imagem.
mkdir Montagem de recuperaçãoEm seguida, monte o arquivo de imagem usando:
sudo montar -o recuperação de loop.img ~ / Montagem de recuperaçãoO sinalizador -o indica as opções, enquanto a opção loop é usada para tratar o arquivo de imagem como um dispositivo de bloco.
Agora você tem acesso ao conteúdo do arquivo de imagem, conforme exibido na imagem a seguir.
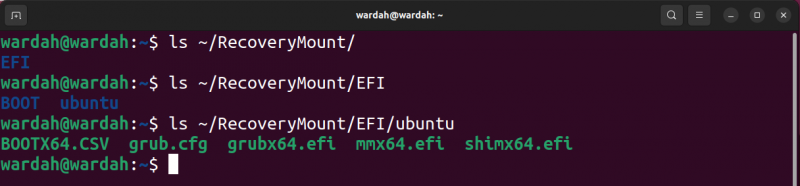
Para desmontar o bloco, use o quantidade comando.
sudo quantidade ~ / Montagem de recuperaçãoCaracterísticas avançadas
Para iniciar a recuperação a partir de um ponto específico, use o -eu bandeira ou –posição de entrada . Deve estar em bytes, por padrão é 0 bytes. Isto é importante para retomar a cópia a partir de um ponto específico. Por exemplo, se você quiser iniciar o processo de cópia a partir dos 10 GB, use o comando a seguir.
sudo ddrescue -i10GiB / desenvolvedor / sda arquivo de imagem.img arquivo de log.logPara definir o tamanho máximo do dispositivo de entrada, o -s bandeira será usada. O -s significa tamanho e também pode ser usado como -tamanho em bytes. Se a ferramenta não reconhecer o tamanho do arquivo de entrada, use esta opção para especificá-lo.
sudo ddrescue -s10GiB / desenvolvedor / sda arquivo de imagem.img arquivo de log.logO -perguntar Esta opção pode ser bastante útil, pois solicita a confirmação dos blocos de entrada e saída antes de iniciar o processo de cópia. Conforme discutido anteriormente, o sistema atribui nomes dinamicamente aos blocos e eles mudam na reinicialização. Então, nesse caso, esta opção pode ser útil.
sudo ddrescue --perguntar / desenvolvedor / sda arquivo de imagem.img arquivo de log.logAlém disso, uma lista de algumas outras opções é mencionada abaixo:
| -R | -reverter | Para inverter a direção da cópia |
| -q | -bastante | Para suprimir todas as mensagens de saída |
| -em | –detalhado | Para elaborar, todas as mensagens de saída |
| -p | –pré-alocar | Para pré-alocar armazenamento para o arquivo de saída |
| -P | –visualização de dados | As linhas de exibição da última leitura de dados padrão são 3 linhas |
Como funciona o ddrescue
O ddrescue usa um poderoso algoritmo de recuperação que é dividido em quatro fases:
1. Copiando
2. Corte
3. Raspagem
4. Tentando novamente
A execução do algoritmo ddrescue é mostrada na imagem a seguir.

Conclusão
O ddrescue é uma poderosa ferramenta de recuperação usada para recuperar dados de uma unidade corrompida ou com falha para outra unidade, copiando os dados. Ele pode ser instalado facilmente em qualquer distribuição Linux com a ajuda do gerenciador de pacotes padrão. Observe a consideração importante antes de usar esta ferramenta mencionada neste guia. O processo de cópia de dados é simples, desmonte a unidade e use o comando ddrescue com o nome da unidade de origem e o nome da unidade de destino. Não se esqueça de utilizar o arquivo de log, pois é bastante útil para retomar o processo de recuperação.