Exemplo 1:
O “iostream” é o primeiro arquivo de cabeçalho aqui onde as funções do C++ são declaradas. Em seguida, adicionamos o arquivo de cabeçalho “vetor” que está incluído aqui para que possamos trabalhar com o vetor e a função para operar em vetores. Então, “std” é o namespace que inserimos aqui, então não precisamos colocar esse “std” com todas as funções individualmente neste código. Então, o “main()” é invocado aqui. Abaixo disso, criamos um vetor do tipo de dados “int” com o nome “myNewData” e inserimos nele alguns valores inteiros.
Depois disso, colocamos o loop “for” e utilizamos a palavra-chave “auto” dentro dele. Agora, este iterador detectará o tipo de dados dos valores aqui. Pegamos os valores do vetor “myNewData” e os salvamos na variável “data” e também os exibimos aqui à medida que adicionamos esses “dados” no “cout”.
Código 1:
#include
#incluir
usando espaço para nome padrão ;
interno principal ( ) {
vetor < interno > meusNovosDados { onze , 22 , 33 , 44 , 55 , 66 } ;
para ( auto dados : meusNovosDados ) {
corte << dados << fim ;
}
}
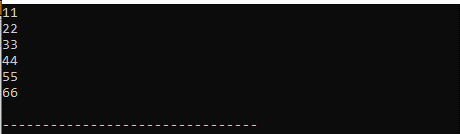
Saída :
Vimos todos os valores deste vetor que estão impressos aqui. Imprimimos esses valores utilizando o loop “for” e colocando a palavra-chave “auto” dentro dele.
Exemplo 2:
Aqui, adicionamos “bits/stdc++.h”, pois contém todas as declarações de função. Então, colocamos o namespace “std” aqui e então invocamos “main()”. Abaixo disso, inicializamos um “conjunto” de “string” e o nomeamos como “myString”. Então, na próxima linha, inserimos os dados da string nela. Inserimos alguns nomes de frutas neste conjunto usando o método “insert()”.
Usamos o loop “for” abaixo dele e colocamos a palavra-chave “auto” dentro dele. Depois disso, inicializamos um iterador com o nome “my_it” com a palavra-chave “auto” e atribuímos “myString” a ele junto com a função “begin()”.
Então, colocamos uma condição que é “my_it” diferente de “myString.end()” e incrementamos o valor do iterador usando “my_it++”. Depois disso, colocamos o ”*my_it” no “cout”. Agora, ele imprime os nomes das frutas de acordo com a sequência alfabética, e o tipo de dados é detectado automaticamente quando colocamos a palavra-chave “auto” aqui.
Código 2:
#incluirusando espaço para nome padrão ;
interno principal ( )
{
definir < corda > minhaString ;
minhaString. inserir ( { 'Uvas' , 'Laranja' , 'Banana' , 'Pera' , 'Maçã' } ) ;
para ( auto meu_it = minhaString. começar ( ) ; meu_it ! = minhaString. fim ( ) ; meu_it ++ )
corte << * meu_it << ' ' ;
retornar 0 ;
}
Saída:
Aqui, podemos notar que os nomes das frutas são exibidos em sequência alfabética. Todos os dados que inserimos no conjunto de strings são renderizados aqui porque utilizamos “for” e “auto” no código anterior.

Exemplo 3:
Como “bits/stdc++.h” já possui todas as declarações de função, nós o adicionamos aqui. Depois de adicionar o namespace “std”, chamamos “main()” deste local. O “conjunto” de “int” que estabelecemos a seguir é denominado “myIntegers”. Em seguida, adicionamos os dados inteiros na linha seguinte. Usamos o método “insert()” para adicionar alguns inteiros a esta lista. A palavra-chave “auto” agora é inserida no loop “for” que é utilizado abaixo dela.
A seguir, usamos a palavra-chave “auto” para inicializar um iterador com o nome “new_it”, atribuindo a ele as funções “myIntegers” e “begin()”. A seguir, configuramos uma condição que afirma que “my_it” não deve ser igual a “myIntegers.end()” e usamos “new_it++” para aumentar o valor do iterador. A seguir, inserimos “*new_it” nesta seção “cout”. Ele imprime os inteiros em ordem crescente. À medida que a palavra-chave “auto” é inserida, ela detecta automaticamente o tipo de dados.
Código 3:
#incluirusando espaço para nome padrão ;
interno principal ( )
{
definir < interno > meus inteiros ;
meus inteiros. inserir ( { Quatro cinco , 31 , 87 , 14 , 97 , vinte e um , 55 } ) ;
para ( auto novo_it = meus inteiros. começar ( ) ; novo_it ! = meus inteiros. fim ( ) ; novo_it ++ )
corte << * novo_it << ' ' ;
retornar 0 ;
}
Saída :
Os inteiros são mostrados aqui em ordem crescente, conforme visto a seguir. Como usamos os termos “for” e “auto” no código anterior, todos os dados que colocamos no conjunto inteiro são renderizados aqui.

Exemplo 4:
Os arquivos de cabeçalho “iostream” e “vetor” são incluídos enquanto trabalhamos com os vetores aqui. O namespace “std” é então adicionado e chamamos “main()”. Em seguida, inicializamos um vetor do tipo de dados “int” com o nome “myVectorV1” e adicionamos alguns valores a este vetor. Agora, colocamos o loop “for” e utilizamos “auto” aqui para detectar o tipo de dados. Acessamos pelos valores do vetor e depois os imprimimos colocando “valueOfVector” no “cout”.
Depois disso, colocamos outro “for” e o “auto” dentro dele e inicializamos com “&& valueOfVector: myVectorV1”. Aqui acessamos pela referência e depois imprimimos todos os valores colocando “valueOfVector” no “cout”. Agora, não precisamos inserir o tipo de dados para ambos os loops, pois utilizamos a palavra-chave “auto” dentro do loop.
Código 4:
#include#incluir
usando espaço para nome padrão ;
interno principal ( ) {
vetor < interno > meuVetorV1 = { 0 , 1 , 2 , 3 , 4 , 5 , 6 , 7 , 8 , 9 , 10 } ;
para ( auto valorDeVetor : meuVetorV1 )
corte << valorDeVetor << ' ' ;
corte << fim ;
para ( auto && valorDeVetor : meuVetorV1 )
corte << valorDeVetor << ' ' ;
corte << fim ;
retornar 0 ;
}
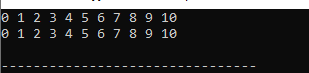
Saída:
Todos os dados do vetor são exibidos. Os números que aparecem na primeira linha são aqueles que acessamos por valores, e os números que aparecem na segunda linha são aqueles que acessamos por referência no código.
Exemplo 5:
Após chamar o método “main()” neste código, inicializamos dois arrays que são “myFirstArray” de tamanho “7” com o tipo de dados “int” e “mySecondArray” com o tamanho “7” do “double” tipo de dados. Inserimos os valores em ambos os arrays. No primeiro array, inserimos os valores “inteiros”. No segundo array, adicionamos os valores “duplos”. Depois disso, utilizamos o “for” e inserimos o “auto” neste loop.
Aqui, usamos um loop “range base for” para “myFirstArray”. Em seguida, colocamos “myVar” no “cout”. Abaixo disso, colocamos um loop novamente e utilizamos o loop “range base for”. Este loop é para “mySecondArray” e então também imprimimos os valores desse array.
Código 5:
#includeusando espaço para nome padrão ;
interno principal ( )
{
interno meuPrimeiroArray [ 7 ] = { quinze , 25 , 35 , Quatro cinco , 55 , 65 , 75 } ;
dobro meuSegundoArray [ 7 ] = { 2,64 , 6h45 , 8,5 , 2,5 , 4,5 , 6.7 , 8,9 } ;
para ( const auto & minhaVar : meuPrimeiroArray )
{
corte << minhaVar << ' ' ;
}
corte << fim ;
para ( const auto & minhaVar : meuSegundoArray )
{
corte << minhaVar << ' ' ;
}
retornar 0 ;
}
Saída:
Todos os dados de ambos os vetores são exibidos neste resultado aqui.

Conclusão
O conceito “for auto” é estudado detalhadamente neste artigo. Explicamos que “auto” detecta o tipo de dados sem mencioná-lo. Exploramos vários exemplos neste artigo e também fornecemos a explicação do código aqui. Explicamos profundamente o funcionamento desse conceito “para automóveis” neste artigo.