Método Pandas Set_Option
Hoje, veremos como usar a função “pd.set_option()” para exibir todas as colunas no Pandas Dataframe ao apresentá-lo em sua ferramenta Spyder. Para usar o “pd.set_option()”, seguimos a sintaxe dada:

Vamos começar a aprender o conceito com a ajuda da implementação prática do programa Python.
Exemplo: utilizando o método Pandas Set_Option para exibir todas as colunas
Esta demonstração é um guia para exibir todas as colunas em um DataFrame utilizando o Pandas “set_option()”. Vamos deixar claros os detalhes de cada passo para a implementação deste método Python.
O primeiro requisito para a implementação prática do script Python é descobrir a melhor ferramenta onde você executa seu programa. A ferramenta que usamos para nossa ilustração é a ferramenta “Spyder”. Lançamos a ferramenta e começamos a trabalhar no script Python.
Começando com o código, inicialmente precisamos importar as bibliotecas de pré-requisitos que precisamos neste programa. A primeira biblioteca que carregamos em nosso arquivo Python é a biblioteca Pandas, pois as funções que usamos aqui são fornecidas pelo Pandas. Nós apelidamos esta biblioteca como “pd”. A segunda biblioteca que carregamos é a biblioteca NumPy. NumPy (Numerical Python) é um pacote de computação numérica desenvolvido sobre programação Python. A seção Importar NumPy do código direciona o Python para integrar o módulo NumPy em seu arquivo Python atual. A parte “as np” do script instrui o Python a atribuir ao NumPy a abreviação “np”. Ele permite que você utilize os métodos NumPy digitando “np.function_name” em vez de NumPy.
Agora, começamos com o código principal. A necessidade principal e fundamental do nosso programa é o Pandas DataFrame. Assim, exibimos todas as colunas que ele contém. Agora, você decide se deseja criar um DataFrame com valores especificados ou se precisa importar um arquivo CSV. O que escolhemos para esta instância é criar um DataFrame com valores NaN. Invocamos o método “pd.DataFrame()” para construir um DataFrame. Aqui, fornecemos dois parâmetros – “índice” e “colunas”. O argumento “index” refere-se às linhas, o que significa que definimos as linhas para o DataFrame.
Atribuímos o parâmetro “index” e a função NumPy “np.arange() com uma contagem de valor de “6”. Ele gera seis linhas para o DataFrame. Ele preenche todas as entradas com valores NaN, pois não fornecemos nenhum valor. O argumento “columns”, como o nome especifica, é usado para definir as colunas para o DataFrame. Também é atribuída a função “np.arange()” com contagem de valor “25” para as colunas. Assim, ele constrói 25 colunas para o DataFrame.
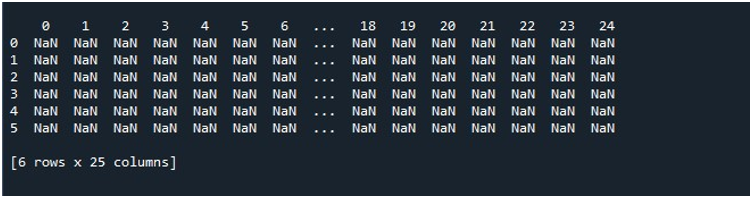
Conseqüentemente, quando chamamos a função “pd.DataFrame()”, temos um DataFrame com 25 colunas e 6 linhas preenchidas com valores nulos. Para a necessidade de preservar este DataFrame, somos obrigados a construir um objeto DataFrame que armazene seu conteúdo. Portanto, criamos um objeto DataFrame “random” e atribuímos a ele o resultado que obtemos do método “pd.DataFrame()”. Agora, você certamente quer ver o DataFrame sendo gerado. Python nos fornece um método para visualizar a saída na tela que é a função “print()”. Invocamos este método passando o objeto DataFrame “random” como seu parâmetro.
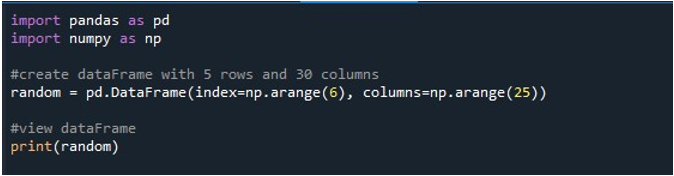
Quando executamos este trecho de código, obtemos nosso DataFrame com valores NaN exibidos no terminal. Aqui, podemos observar que algumas das primeiras colunas e apenas algumas do final são visíveis. Todas as colunas intermediárias são truncadas. Por padrão, ele oculta algumas das linhas e colunas para evitar criar uma frustração para o usuário exibindo grandes conjuntos de dados.
Você pode até verificar o número de colunas totais em um DataFrame usando a função “len()” do Pandas. Escreva a função “len()” no console da sua ferramenta “Spyder”. Escreva o nome do DataFrame entre seus parênteses com a propriedade “.columns”. Ele nos retorna o comprimento total das colunas em seu DataFrame.

Ele retorna o comprimento do nosso DataFrame que é 25.
Agora, a próxima e principal tarefa é alterar a opção padrão para exibir a saída. Pode haver circunstâncias em que você queira visualizar todo o DataFrame no terminal. Por causa dos valores padrão, muitas entradas ficam truncadas, o que causa decepção para o usuário. Você aprenderá aqui como superar esse problema. O Pandas nos fornece uma função “pd.set_option()” para alterar as configurações de exibição padrão. Logo após exibir o DataFrame no console, invocamos o método “pd.set_option()”. Especificamos o parâmetro entre os parênteses desta função que precisamos utilizar para exibir todas as colunas do DataFrame.
Aqui, usamos o “display.max_columns” para exibir o máximo de colunas em nosso DataFrame. Também podemos definir o valor para este parâmetro, ou seja, o máximo de colunas que você deseja exibir. Nós, por outro lado, definimos o “display.max_columns” para “None” que exibe todas as colunas do DataFrame com comprimento máximo. Por fim, empregamos a função “print()” para exibir o DataFrame resultante com todas as colunas visíveis no terminal.
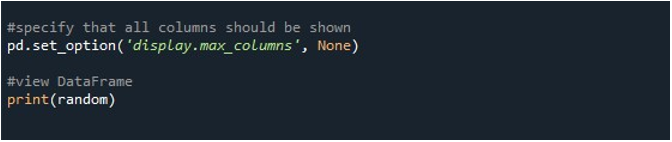
Ao clicar na opção “Executar arquivo” na ferramenta “Spyder”, podemos visualizar um DataFrame sendo exibido. Este DataFrame tem seis linhas e o número de colunas que ele contém é 25. Não há colunas truncadas, pois a função “pd.set_option()” com comprimento máximo de coluna está habilitada agora.
Podemos até redefinir a opção de exibição porque, uma vez que definimos o comprimento de exibição para o máximo, ele continua exibindo os DataFrames com todas as colunas desse arquivo Python específico. Para isso, utilizamos os Pandas “pd.reset_option()”. Chamamos esta função e fornecemos o “display.max_columns” como parâmetro desta função.

Isso nos dá as configurações de exibição iniciais para o DataFrame fornecido.
Conclusão
Ver a saída completa no terminal com um grande conjunto de dados às vezes nos coloca em apuros quando as configurações padrão da ferramenta contrastam com as necessidades do usuário. Para resolver esse contratempo, o Pandas nos fornece o método “pd.set_option()”. Neste guia de aprendizado, apresentamos esse método e a necessidade de empregá-lo. Demonstramos o tópico com os códigos de amostra Python praticamente compilados e executados. Renderizamos os resultados da ilustração realizada em “Spyder”. Explicamos como exibir todas as colunas do DataFrame no console alterando as configurações padrão e redefinindo todas as configurações para inicial. Dar uma atenção totalmente focada à implementação prática do módulo permite que você o utilize sempre que encontrar esse problema.