Os dados são coletados em grande número diariamente e o gerenciamento de big data é o caso de uso mais importante do mecanismo Elasticsearch. Os dados são armazenados no banco de dados de análise em tempo real e o usuário pode extrair dados para encontrar conhecimento útil usando consultas. O usuário pode aplicar consultas para encontrar dados de vários índices e exibi-los em um único depósito do banco de dados relacional.
Este guia explicará as agregações do Elasticsearch com exemplos usando diferentes agregações.
O que é a agregação do Elasticsearch?
No Elasticsearch, agregação é o processo de combinar ou agrupar os campos para extrair informações do banco de dados relacional. A agregação no Elasticsearch pode ser considerada como o GRUPO POR CLÁUSULA ou AGREGAR() função na linguagem SQL.
Como usar a agregação do Elasticsearch?
Para usar a agregação no Elasticsearch, o usuário precisa ter um conhecimento básico de seu banco de dados. Vamos explorar a sintaxe e sua implementação prática:
Sintaxe
Para encontrar os dados do banco de dados, a sintaxe da agregação no Elasticsearch engine conforme abaixo:
'aggs' : {'nome_da_agregação' : {
'type_of_aggregation' : {
'campo' : 'document_field_name'
}
Os trechos acima:
-
- Ele usa o “ aggs ” palavra-chave que explica o uso de agregação na consulta.
- O nome_da_agregação é definido pelo usuário de acordo com as informações necessárias.
- Depois disso, o type_of_aggregation é usado para obter dados.
- A última linha usa o campo palavra-chave que é seguida pelo nome do atributo do documento.
Exemplo 1: agregação em dados de amostra do Kibana
Esta seção explica a agregação com a ajuda de um exemplo usando os dados de amostra do Kibana conectando-se a ele primeiro. Depois disso, basta entrar no “ ferramentas de desenvolvimento ” pesquisando-o na barra de pesquisa e clicando nele:
Obter dados de dados de amostra
Basta usar o seguinte comando para buscar os dados do “ kibana_sample_data_logs ” índice no console do Dev Tools:
PEGAR / kibana_sample_data_logs / _procurar
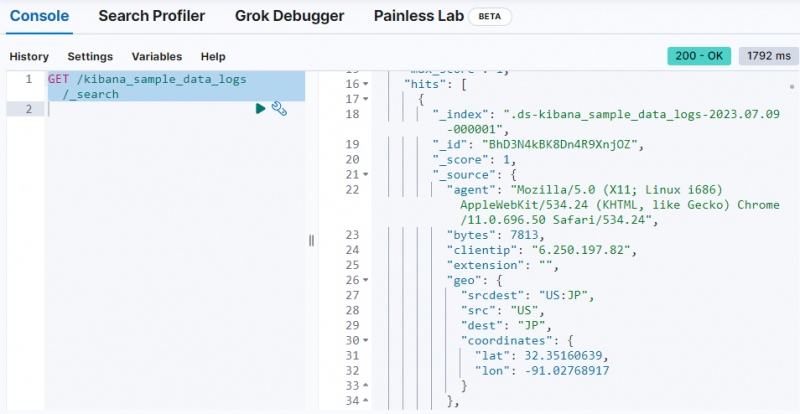
A saída mostra que os dados foram obtidos do “ kibana_sample_data_logs ” índice.
O código a seguir usa um PEGAR pedido no “ kibana_sample_data_log ” para pesquisá-lo usando a agregação value_count no “ clientela ' campo:
PEGAR / kibana_sample_data_logs / _procurar{ 'tamanho' : 0 ,
'aggs' : {
'ip_count' : {
'valor_contagem' : {
'campo' : 'cliente'
}
}
}
}
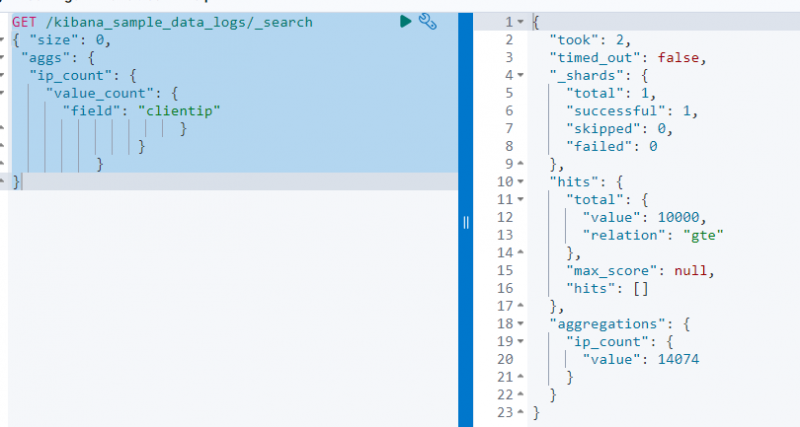
A captura de tela acima exibe a agregação no clientela campo com o valor 14074 .
Agregações importantes
Algumas das agregações importantes que estão sendo usadas para localizar dados com eficiência no banco de dados são mencionadas abaixo:
Os exemplos a seguir explicam as agregações mencionadas acima usando o PEGAR pedido do “ kibana_sample_data_ecommerce ” índice:
Agregação de Cardinalidade
O código a seguir usa o “ cardinalidade ” agregação no “ sku ” campo dos dados de comércio eletrônico. A execução desse código obterá a agregação de valor único para obter os SKUs exclusivos do banco de dados Elasticsearch:
PEGAR / kibana_sample_data_ecommerce / _procurar{
'tamanho' : 0 ,
'aggs' : {
'unique_skus' : {
'cardinalidade' : {
'campo' : 'sku'
}
}
}
}
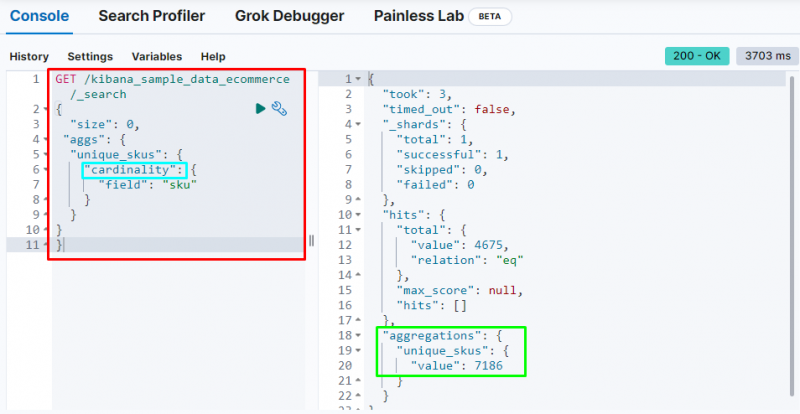
Ele exibe o cardinalidade agregação encontrando o 7186 valores do índice.
Agregação de estatísticas
Outra agregação importante é o “ Estatísticas ” agregação que é usada para obter o “ contar ”, “ min ”, “ máximo ”, “ média ', e ' soma ” estatísticas do “ quantidade total ' campo:
PEGAR / kibana_sample_data_ecommerce / _procurar{
'tamanho' : 0 ,
'aggs' : {
'quantity_stats' : {
'Estatísticas' : {
'campo' : 'quantidade total'
}
}
}
}
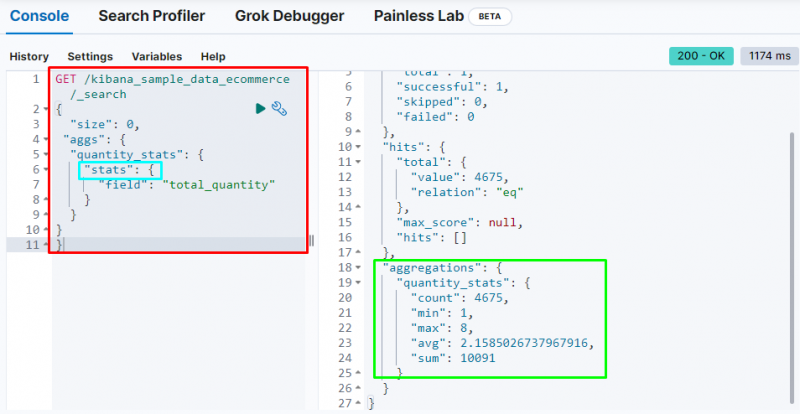
A captura de tela acima exibe as estatísticas na saída do “ quantidade total ' campo.
Filtrar Agregação
A agregação de filtro é usada para filtrar dados com base em um termo ou frase do banco de dados conforme o seguinte código os contém:
PEGAR / kibana_sample_data_ecommerce / _procurar{ 'tamanho' : 0 ,
'aggs' : {
'filter_aggregation' : {
'filtro' : {
'prazo' : {
'do utilizador' : 'eddie' } } ,
'aggs' : {
'preço_médio' : {
'média' : {
'campo' : 'produtos.preço' } }
} } } }
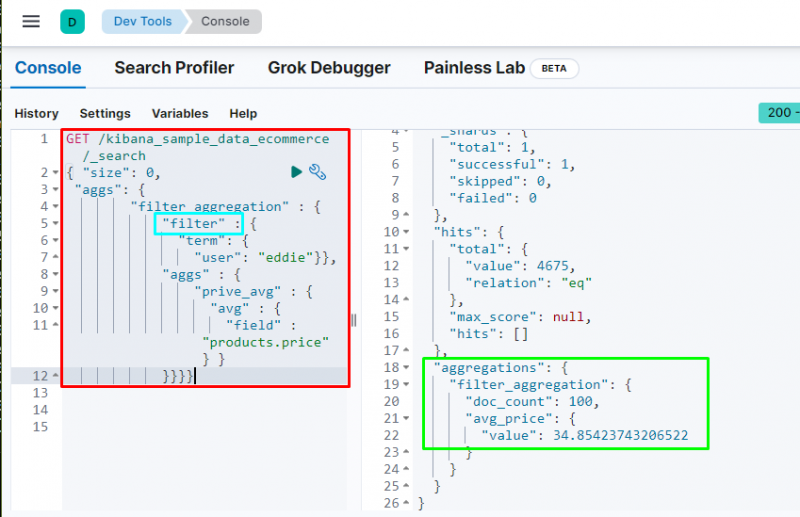
A execução do código filtrará os dados com base no “ eddie ” usuário e exibe o preço médio dos itens comprados. A captura de tela acima mostra que o do utilizador encontrou 100 vezes a partir dos dados e do valor do média _ preço agregação.
Agregação de termos
O termo agregação cria um depósito e armazena dados do campo no depósito e o código a seguir usa o “ do utilizador ” campo para armazenar seus dados no balde:
PEGAR / kibana_sample_data_ecommerce / _procurar{
'tamanho' : 0 ,
'aggs' : {
'Term_Aggregation' : {
'termos' : {
'campo' : 'do utilizador'
}
}
}
}
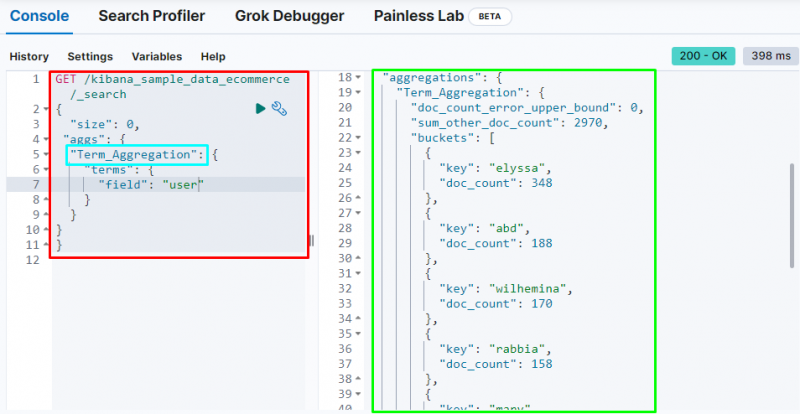
A captura de tela a seguir mostra que a agregação de termos criou depósitos para cada usuário e sua contagem de documentos.
Isso é tudo sobre a agregação do Elasticsearch e diferentes agregações importantes.
Conclusão
No Elasticsearch, a agregação é usada para obter dados dos documentos agregados e esses documentos são extraídos de um campo específico. Existem algumas agregações importantes que estão sendo usadas para obter insights úteis dos índices são explicados. Este guia explicou a agregação do Elasticsearch e demonstrou o processo de uso da agregação do Elasticsearch.