Escalabilidade
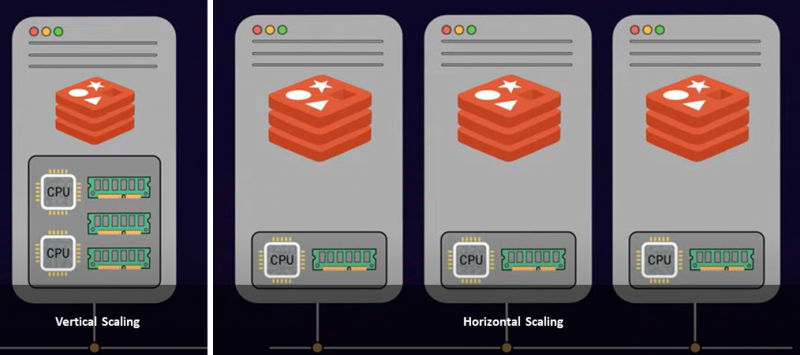
Há duas abordagens comuns para escalar um servidor: escala vertical e escala horizontal. O dimensionamento vertical ou aumento vertical é onde você adiciona mais potência e recursos ao seu servidor, como mais CPUs, memória e armazenamento, o que é caro. Por outro lado, o dimensionamento horizontal adiciona vários nós ao pool de recursos existente. Isso é chamado de expansão. Portanto, com base em suas limitações e requisitos, cabe a você ter uma única instância de servidor maior ou implantar vários nós de servidor.
Suponha que você tenha 100 GB de RAM e precise armazenar 200 GB de dados. Neste caso, você tem duas escolhas:
- Aumente a escala adicionando mais RAM ao sistema
- Dimensione adicionando outra instância de servidor com 100 GB de RAM
Se você atingiu o limite máximo de RAM em sua infraestrutura, a expansão é a abordagem ideal. Além disso, a expansão aumentará a taxa de transferência do banco de dados em uma margem enorme.
Fragmentação Redis
É um fato conhecido que o Redis opera em um único thread. Portanto, o Redis não é capaz de utilizar vários núcleos da CPU do seu servidor para processar comandos. Portanto, adicionar mais núcleos de CPU não oferece muito rendimento ou desempenho com o Redis. Não é o caso de dividir seus dados entre várias instâncias do servidor. Adicionar vários servidores e distribuir o conjunto de dados entre eles permite o processamento paralelo das solicitações dos clientes, o que aumenta a taxa de transferência. Além disso, o desempenho geral pode aumentar quase linearmente.
Essa abordagem de dividir ou distribuir dados entre vários servidores com dimensionamento em mente é chamada fragmentação . Todos os servidores que armazenam porções de dados são chamados cacos .
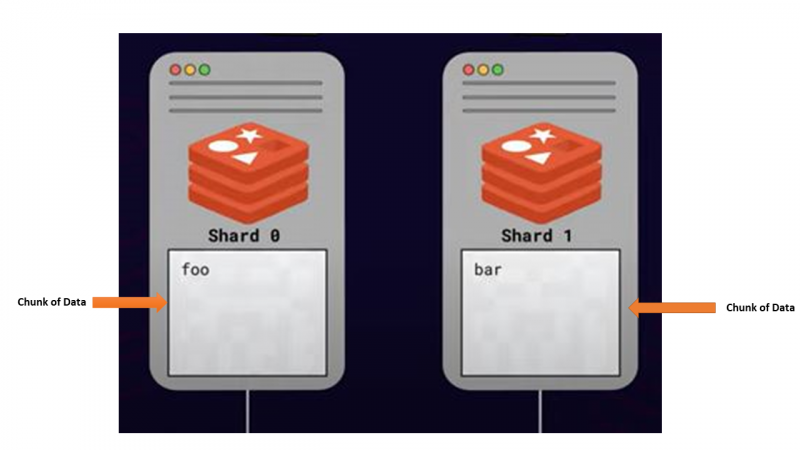
Como é feita a fragmentação — fragmentação algorítmica
Uma das principais preocupações com o sharding era como localizar uma determinada chave entre vários nós do Redis. Como uma determinada chave pode ser armazenada em qualquer estilhaço disponível, consultar todos os estilhaços para localizar uma chave específica não é a melhor opção. Portanto, deve haver uma maneira de mapear cada chave para um fragmento específico, e o Redis usa uma estratégia de fragmentação algorítmica.
A abordagem mais comum é calcular um valor de hash usando o nome e o módulo da chave Redis. Em seguida, divida-o pelos shards Redis disponíveis no sistema.
HASH_SLOT = mod CRC16(chave) 16384É uma solução bastante boa, desde que o número total de fragmentos seja constante. Sempre que você adiciona uma nova instância do servidor Reids, o valor resultante para uma determinada chave pode mudar, pois o número total de fragmentos aumentou. Ele acabará consultando o fragmento Redis errado. Portanto, você deve seguir o processo de resharding calculando o novo shard para cada chave e transferindo dados para o servidor correto, o que é complicado e não é uma tarefa trivial se a contagem total de shards aumentar de tempos em tempos.
O Redis usa uma nova entidade lógica chamada slot de hash para prevenir este problema. Vários slots de hash estão disponíveis para um determinado shard e um único slot de hash pode conter várias chaves Redis. Existem 16384 slots de hash em um cluster de banco de dados Redis que permanecem inalterados. A divisão do módulo é feita com o número de slots de hash em vez da contagem de fragmentos. Ele fornece a posição correta do slot de hash para a chave especificada, mesmo quando o número de estilhaços aumenta. Ele simplifica o processo de resharding movendo os slots de hash de um estilhaço para o novo que divide os dados nas diferentes instâncias do Redis conforme o requisito.
Benefícios do Redis Sharding
O sharding Redis permite vários benefícios para seu sistema de banco de dados com alterações mínimas.
Alto rendimento
Como o Redis é de thread único, o processamento de várias solicitações de clientes não pode ser processado em paralelo usando vários núcleos de CPU. Portanto, adicionar novos shards ou instâncias de servidor garante que você possa executar operações do Redis em paralelo. Ele aumenta as operações por segundo em seu banco de dados Redis, o que eventualmente oferece alta taxa de transferência.
Alta disponibilidade
Com a abordagem de sharding, o cluster Redis pode configurar uma arquitetura de réplica mestre que garante alta disponibilidade e durabilidade.
Réplicas de leitura
A fragmentação permite que você mantenha uma cópia exata de seus dados e forneça operações de leitura por meio de instâncias Redis separadas, o que aumenta o desempenho da execução da consulta de leitura.
Além desses benefícios, o sharding pode causar situações de cérebro dividido quando você tem um número par de shards no cluster Redis. Portanto, é recomendável manter um número ímpar de shards em seu cluster Redis.
Conclusão
Para resumir, o sharding do Redis é a divisão de dados entre vários servidores, o que permite dimensionamento e alta taxa de transferência para seu banco de dados. Conforme discutido, o Redis usa uma estratégia de fragmentação algorítmica para apontar as solicitações do cliente para o fragmento correto. Isso tem algumas desvantagens quando o número total de fragmentos aumenta. Portanto, em vez do número total de estilhaços, o Redis usa o número de slots de hash para calcular o estilhaço apropriado. Com a introdução do sharding, os bancos de dados Redis fornecem alta disponibilidade, alta taxa de transferência e alto desempenho.