Este artigo fornece instruções para implementar o Intelligent-Tiering para otimizar custos no bucket S3.
O que é camada inteligente no bucket S3?
Os dados estão crescendo exponencialmente em todo o mundo. Alguns desses dados são acessados diariamente, enquanto o restante é necessário apenas ocasionalmente. Como o S3 é um dos serviços mais populares da AWS para armazenamento de dados, a AWS introduziu uma classe de armazenamento conhecida como “Escalação Inteligente” para cortar gastos do S3 com armazenamento de dados. Saiba mais sobre as diferentes classes de armazenamento de buckets S3 consultando este artigo: “Uma visão geral das diferentes classes de armazenamento no S3” .
O Intelligent-Tiering pode otimizar os gastos do S3 monitorando os padrões de acesso aos dados. Este recurso é eficiente o suficiente para determinar quais dados são acessados com frequência ou ocasionalmente. Com base nesses padrões, ele os identifica e coloca automaticamente no nível mais econômico, sem sobrecarga operacional ou redução de desempenho.
Como otimizar os custos de armazenamento de dados no Amazon S3 com camadas inteligentes?
Dependendo dos padrões de acesso aos dados, os objetos que raramente são acessados serão colocados no nível de acesso de baixo custo para fins de custo ideal. Se o objeto for acessado pelo usuário, ele será automaticamente e imediatamente movido de volta para o Nível de acesso frequente para disponibilidade sem custos adicionais:
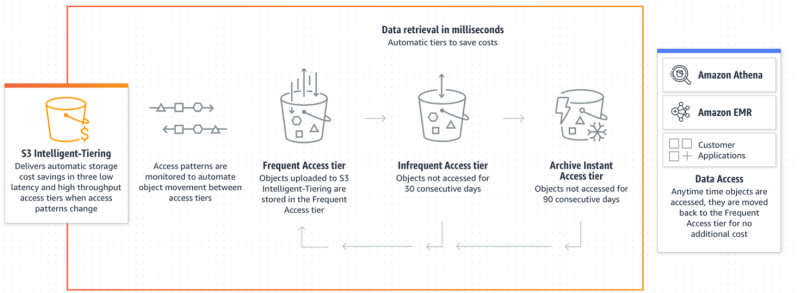
O Intelligent Tiering é uma escolha viável e ideal para os usuários quando se trata de otimizar custos para padrões imprevisíveis de acesso a dados. A seguir estão as etapas nas quais podemos implementar a classe de armazenamento Intelligent-Tiering para eficiência de custos:
Etapa 1: Painel S3
Para obter uma solução econômica para armazenamento de dados com o bucket S3, pesquise o 'S3' serviço na barra de pesquisa da AWS e clique nele nos resultados exibidos:
Etapa 2: criar intervalo
Clique no “Criar balde” botão no Consola S3 :
Etapa 3: configurações gerais
Na interface exibida, forneça um identificador único para o balde S3 no “Configurações gerais” seção:
Etapa 4: toque no botão “Criar balde”
Mantendo os padrões, clique no botão “Criar balde” botão localizado na parte inferior da interface:
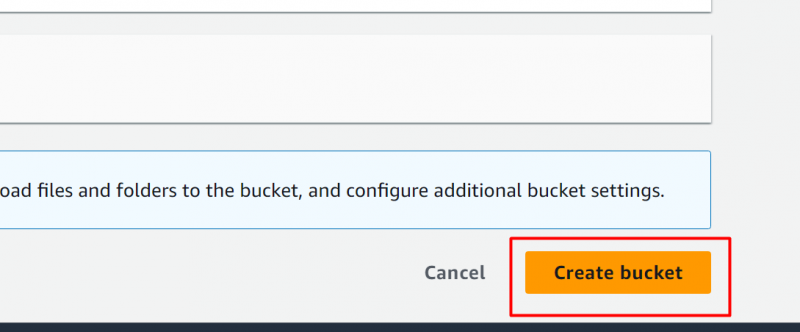
O bucket foi criado com sucesso. A seguir, faremos upload de um arquivo para este bucket. Clique no nome do bucket para navegar até a interface de upload do arquivo:
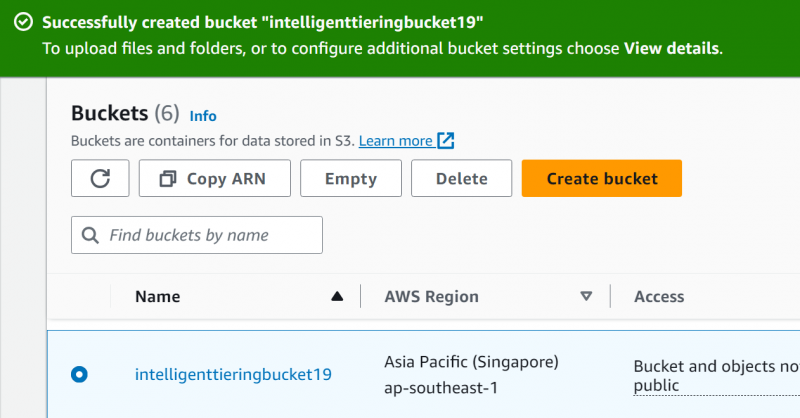
Etapa 5: fazer upload de arquivos
Clique no 'Carregar' botão na interface exibida:
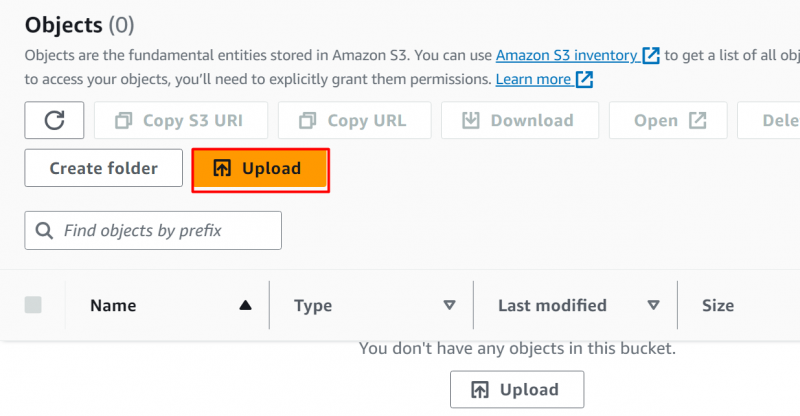
Para escolher os arquivos, clique no 'Adicionar arquivos' botão e selecione os arquivos/pastas do seu dispositivo. O arquivo foi carregado no bucket S3:
Navegue até o “Propriedades” bloquear e selecione o “ Camadas inteligentes” opção do Classe de armazenamento seção :
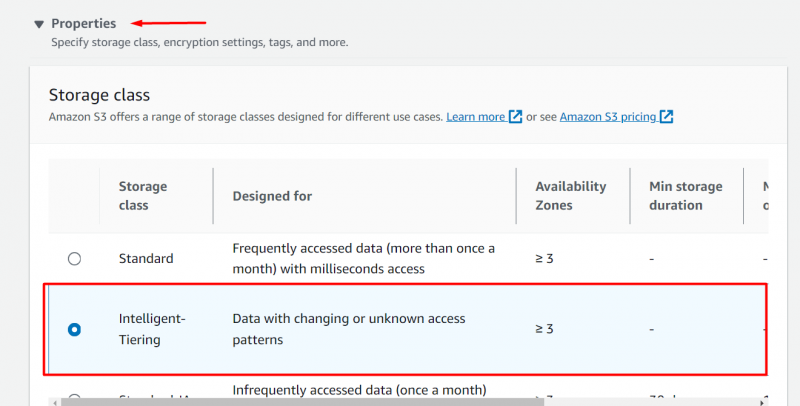
Ao manter o resto do configurações inalteradas , Clique no 'Carregar' botão localizado na parte inferior da interface:
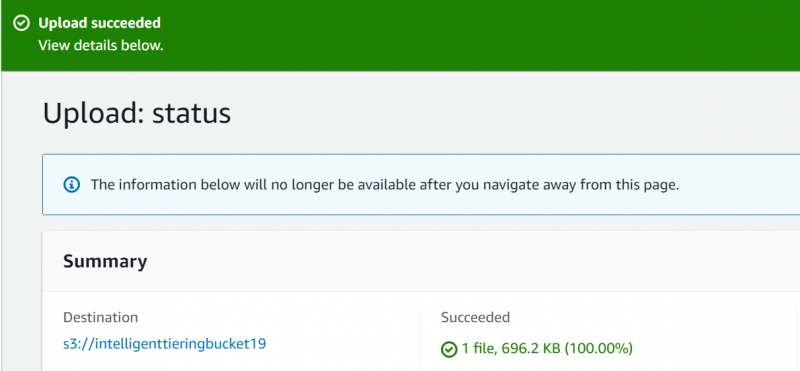
AWS exibirá um Mensagem de confirmação que indica que o arquivo foi carregado com sucesso:
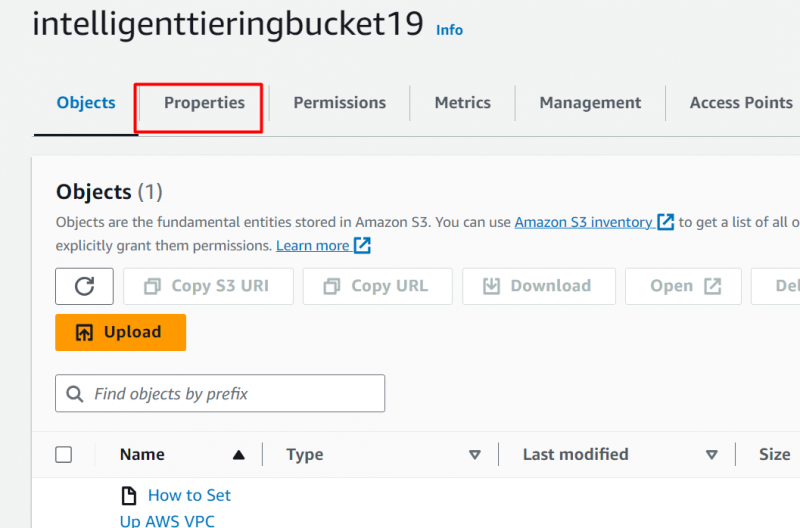
Etapa 6: toque na guia “Propriedades”
Após o upload do arquivo, clique no botão “Propriedades” aba:
Etapa 7: configurações de arquivamento de camadas inteligentes
De Propriedades interface, role para baixo até a “Configurações do Intelligent-Tiering Archive” seção e clique no “Criar configurações” botão:
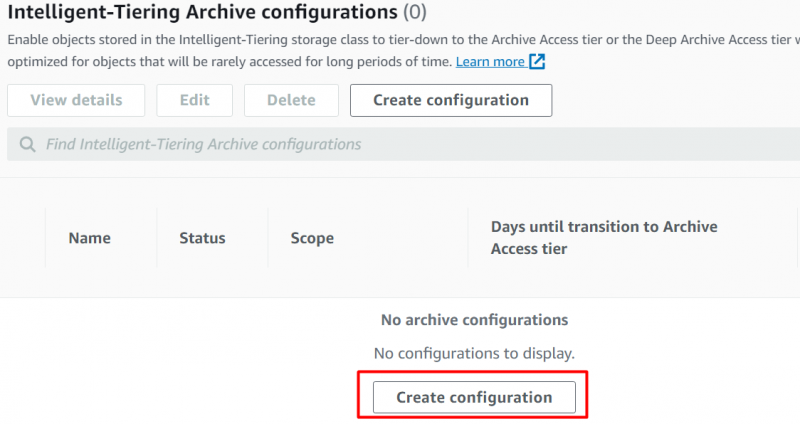
Proporciona a 'Nome' e a 'Prefixo' para configurações na próxima interface exibida:
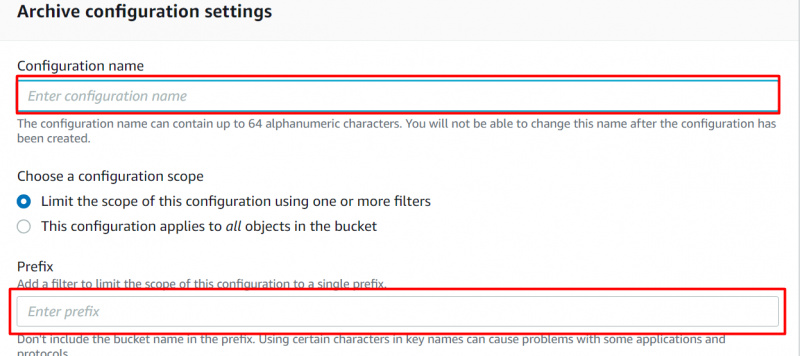
Etapa 8: nível de acesso ao arquivo
Navegue até o “Arquivar ações de regra” seção para configurar quando os objetos devem ser movidos. Ative a opção a seguir e forneça um número de dias consecutivos após os quais você deseja mover os objetos para o “Nível de acesso ao arquivo” :
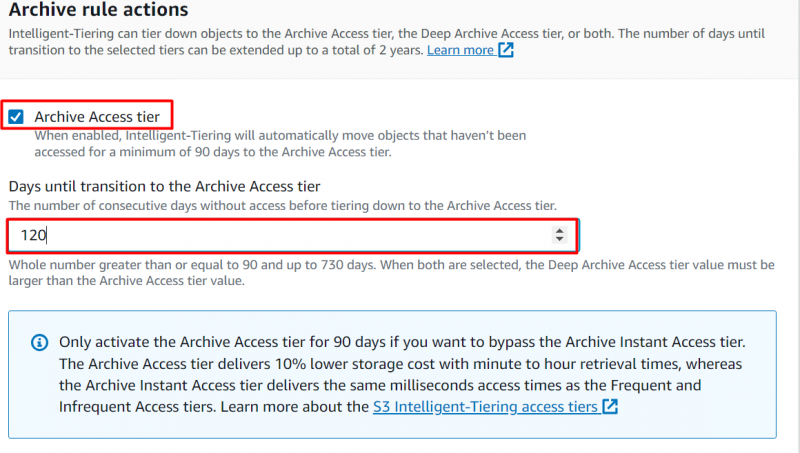
Observação : Se um objeto não for acessado por no mínimo 90 dias, o objeto será movido automaticamente para o nível de acesso ao arquivo. Os usuários podem estender esse período para um máximo de 730 dias.
Etapa 9: nível de acesso profundo ao arquivo
Assim como o Archive Access Tier, o usuário também pode configurar o Deep Archive Access Tier. Ao ativar a opção a seguir, forneça o número de dias após os quais o objeto deve ser movido para o Deep Archive Access Tier. Depois de fornecer o número de dias, clique no botão 'Criar' botão:
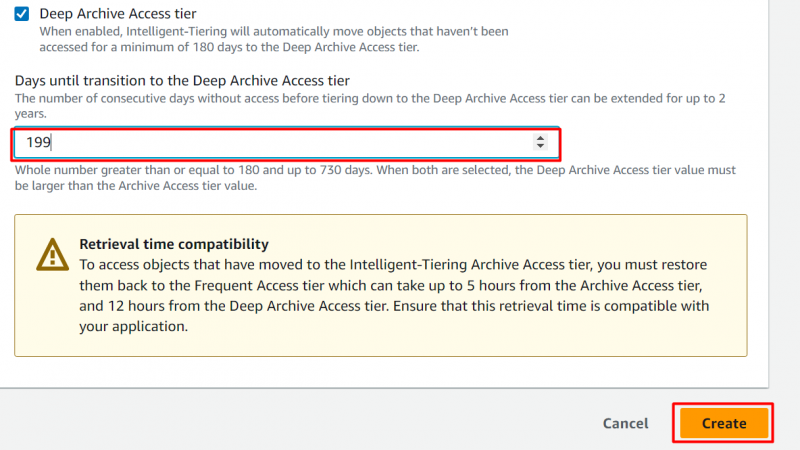
Observação : no Deep Archive Access Tier, os objetos que não foram acessados por um mínimo de 180 dias são movidos para esta camada. Os usuários podem personalizar esse número de dias para um máximo de 730 dias .
As configurações foram feitas com sucesso. Agora, quando os objetos carregados não forem acessados pelo usuário durante o tempo especificado, os dados serão movidos automaticamente para diferentes níveis para minimizar os gastos:
Isso é tudo deste guia.
Conclusão
Para otimização de custos com o bucket S3, selecione a opção Classe de camadas inteligentes ao fazer upload de arquivos e, em seguida, forneça o horário para as respectivas camadas. O Intelligent-Tiering economiza custos ao determinar os objetos acessados com frequência e raramente nas respectivas camadas. Este artigo fornece instruções passo a passo para alcançar a solução com ótimo custo-benefício com um bucket S3.