6.1 Introdução
Os computadores modernos de uso geral são de dois tipos: CISC e RISC. CISC significa Computador com Conjunto de Instruções Complexas. RISK significa Computador com conjunto de instruções reduzido. Os microprocessadores 6502 ou 6510, conforme aplicável ao computador Commodore-64, se assemelham mais à arquitetura RISC do que à arquitetura CISC.
Os computadores RISC geralmente têm instruções em linguagem assembly mais curtas (em número de bytes) em comparação com os computadores CISC.
Observação : Seja lidando com CISC, RISC ou computador antigo, um periférico começa em uma porta interna e sai através de uma porta externa na superfície vertical da unidade de sistema do computador (unidade base) e para o dispositivo externo.
Uma instrução típica de um computador CISC pode ser vista como a junção de várias instruções curtas em linguagem assembly em uma instrução mais longa em linguagem assembly, o que torna a instrução resultante complexa. Em particular, um computador CISC carrega os operandos da memória nos registradores do microprocessador, executa uma operação e depois armazena o resultado de volta na memória, tudo em uma instrução. Por outro lado, são pelo menos três instruções (curtas) para o computador RISC.
Existem duas séries populares de computadores CISC: os computadores com microprocessador Intel e os computadores com microprocessador AMD. AMD significa Micro Dispositivos Avançados; é uma empresa fabricante de semicondutores. As séries de microprocessadores Intel, em ordem de desenvolvimento, são 8086, 8088, 80186, 80286, 80386, 80486, Pentium, Core, i Series, Celeron e Xeon. As instruções em linguagem assembly para os primeiros microprocessadores Intel, como 8086 e 8088, não são muito complexas. No entanto, eles são complexos para os novos microprocessadores. Os microprocessadores AMD recentes para a série CISC são Ryzen, Opteron, Athlon, Turion, Phenom e Sempron. Os microprocessadores Intel e AMD são conhecidos como microprocessadores x86.
ARM significa Máquina RISC Avançada. As arquiteturas ARM definem uma família de processadores RISC adequados para uso em uma ampla variedade de aplicações. Embora muitos microprocessadores Intel e AMD sejam usados em computadores pessoais desktop, muitos processadores ARM servem como processadores incorporados em sistemas críticos de segurança, como freios antibloqueio automotivos e como processadores de uso geral em smartwatches, telefones portáteis, tablets e laptops. . Embora ambos os tipos de microprocessadores possam ser vistos em dispositivos pequenos e grandes, os microprocessadores RISC são encontrados mais em dispositivos pequenos do que em dispositivos grandes.
Palavra de computador
Se for considerado um computador com palavra de 32 bits, isso significa que as informações são armazenadas, transferidas e manipuladas na forma de códigos binários de trinta e dois bits na parte interna da placa-mãe. Isso também significa que os registradores de uso geral no microprocessador do computador têm largura de 32 bits. Os registros A, X e Y do microprocessador 6502 são registros de uso geral. Eles têm oito bits de largura e, portanto, o computador Commodore-64 é um computador de palavras de oito bits.
Algum vocabulário
Computadores X86
Os significados de byte, palavra, palavra dupla, palavra quádrupla e palavra quádrupla são os seguintes para os computadores x86:
- Byte : 8 bits
- Palavra : 16 bits
- Palavra dupla : 32 bits
- Quatro palavras : 64 bits
- Quatro palavras duplas : 128 bits
Computadores ARM
Os significados de byte, meia palavra, palavra e palavra dupla são os seguintes para os computadores ARM:
- Byte : 8 bits
- Torne-se metade : 16 bits
- Palavra : 32 bits
- Palavra dupla : 64 bits
As diferenças e semelhanças entre os nomes (e valores) x86 e ARM devem ser observadas.
Observação : Os números inteiros de sinal em ambos os tipos de computador são complemento de dois.
Localização da memória
Com o computador Commodore-64, um local de memória é normalmente um byte, mas pode ser dois bytes consecutivos ocasionalmente quando se considera os ponteiros (endereçamento indireto). Com um computador x86 moderno, um local de memória é de 16 bytes consecutivos ao lidar com uma palavra quádrupla dupla de 16 bytes (128 bits), 8 bytes consecutivos ao lidar com uma palavra quádrupla de 8 bytes (64 bits), 4 bytes consecutivos ao lidar com uma palavra dupla de 4 bytes (32 bits), 2 bytes consecutivos quando se trata de uma palavra de 2 bytes (16 bits) e 1 byte quando se trata de um byte (8 bits). Com um computador ARM moderno, um local de memória é de 8 bytes consecutivos ao lidar com uma palavra dupla de 8 bytes (64 bits), 4 bytes consecutivos ao lidar com uma palavra de 4 bytes (32 bits), 2 bytes consecutivos ao lidar com uma meia palavra de 2 bytes (16 bits) e 1 byte quando se trata de um byte (8 bits).
Este capítulo explica o que há de comum nas arquiteturas CISC e RISC e quais são suas diferenças. Isso é feito em comparação com o 6502 µP e o computador Commodore-64, onde for aplicável.
6.2 Diagrama de blocos da placa-mãe de um PC moderno
PC significa Computador Pessoal. A seguir está um diagrama de blocos básico genérico para uma placa-mãe moderna com um único microprocessador para um computador pessoal. Representa uma placa-mãe CISC ou RISC.
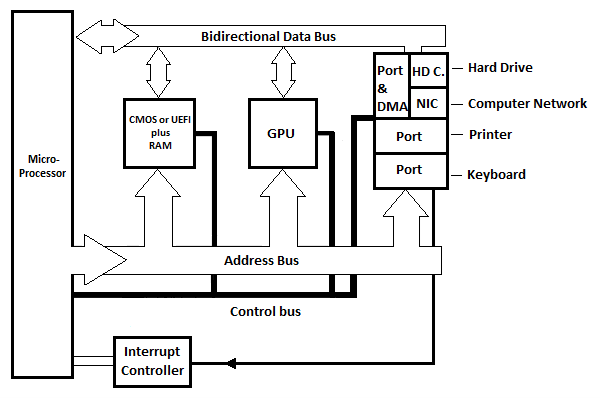
Fig. 6.21 Diagrama de blocos básico da placa-mãe de um PC moderno
Três portas internas são mostradas no diagrama, mas na prática existem mais. Cada porta possui um registro que pode ser visto como a própria porta. Cada circuito de porta possui pelo menos outro registro que pode ser chamado de “registro de status”. O registrador de status indica a porta do programa que está enviando o sinal de interrupção ao microprocessador. Existe um circuito controlador de interrupção (não mostrado) que diferencia as diferentes linhas de interrupção das diferentes portas e possui apenas algumas linhas para o µP.
HD.C no diagrama significa placa de disco rígido. NIC significa Placa de interface de rede. A placa (circuito) do disco rígido está conectada ao disco rígido que está dentro da unidade base (unidade de sistema) do computador moderno. A placa de interface de rede (circuito) é conectada por meio de um cabo externo a outro computador. No diagrama, há uma porta e um DMA (consulte a ilustração a seguir) que estão conectados à placa de disco rígido e/ou à placa de interface de rede. O DMA significa Acesso Direto à Memória.
Lembre-se do capítulo do computador Commodore-64 que para enviar os bytes da memória para a unidade de disco ou outro computador, cada byte deve ser copiado para um registro no microprocessador antes de ser copiado para a porta interna correspondente e, em seguida, automaticamente para o dispositivo. Para receber os bytes da unidade de disco ou de outro computador na memória, cada byte deve ser copiado do registro da porta interna correspondente para um registro do microprocessador antes de ser copiado para a memória. Isso normalmente demora muito se o número de bytes no fluxo for grande. A solução para transferência rápida é a utilização do Acesso Direto à Memória (circuito) sem passar pelo microprocessador.
O circuito DMA fica entre a porta e o HD. C ou placa de rede. Com o acesso direto à memória do circuito DMA, a transferência de grandes fluxos de bytes ocorre diretamente entre o circuito DMA e a memória (RAM) sem a participação contínua do microprocessador. O DMA usa o barramento de endereços e o barramento de dados no lugar do µP. A duração total da transferência é menor do que se o µP hard fosse usado. Tanto HD C. quanto NIC utilizam o DMA quando possuem um grande fluxo de dados (bytes) para transferência com RAM (a memória).
GPU significa Unidade de Processamento Gráfico. Este bloco da placa-mãe é responsável por enviar o texto e as imagens em movimento ou estáticas para a tela.
Com os computadores modernos (PCs), não há memória somente leitura (ROM). Existe, no entanto, o BIOS ou UEFI que é uma espécie de RAM não volátil. As informações no BIOS são, na verdade, mantidas por uma bateria. A bateria é o que realmente mantém o cronômetro do relógio na hora e data certas para o computador. O UEFI foi inventado após o BIOS e substituiu o BIOS, embora o BIOS ainda seja bastante relevante nos PCs modernos. Discutiremos mais sobre isso mais tarde!
Nos PCs modernos, os barramentos de endereço e dados entre o µP e os circuitos das portas internas (e memória) não são barramentos paralelos. São barramentos seriais que necessitam de dois condutores para transmissão em um sentido e outros dois condutores para transmissão no sentido oposto. Isto significa, por exemplo, que 32 bits podem ser enviados em série (um bit após o outro) em qualquer direção.
Se a transmissão serial for apenas em uma direção com dois condutores (duas linhas), isso é dito half-duplex. Se a transmissão serial for em ambas as direções com quatro condutores, um par em cada direção, isso é considerado full-duplex.
Toda a memória do computador moderno ainda consiste em uma série de localizações de bytes: oito bits por byte. Um computador moderno possui um espaço de memória de pelo menos 4 giga bytes = 4 x 210 x 2 10 x 2 10 = 4 x 1.073.741.824 10 bytes = 4 x 1024 10/sub> x 1024 10 x 1024 10 = 4 x 1.073.741.824 10 .
Observação : Embora nenhum circuito temporizador seja mostrado na placa-mãe anterior, todas as placas-mãe modernas possuem circuitos temporizadores.
6.3 Noções básicas de arquitetura de computador x64
6.31 O conjunto de registros x64
O microprocessador de 64 bits da série de microprocessadores x86 é um microprocessador de 64 bits. É bastante moderno substituir o processador de 32 bits da mesma série. Os registros de uso geral do microprocessador de 64 bits e seus nomes são os seguintes:
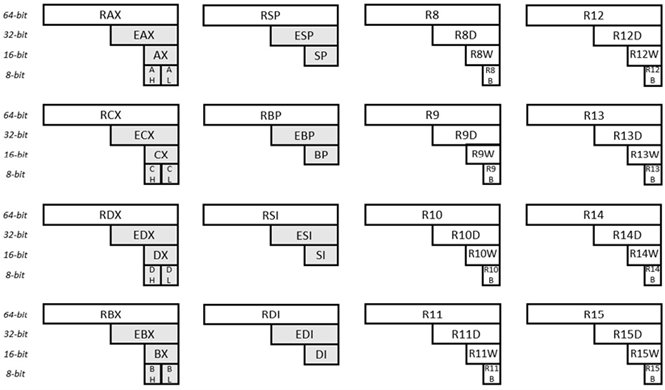
Fig. 6.31 Registros de uso geral para x64
Dezesseis (16) registros de uso geral são mostrados na ilustração fornecida. Cada um desses registros tem largura de 64 bits. Olhando para o registro no canto superior esquerdo, os 64 bits são identificados como RAX. Os primeiros 32 bits deste mesmo registrador (da direita) são identificados como EAX. Os primeiros 16 bits deste mesmo registrador (da direita) são identificados como AX. O segundo byte (da direita) deste mesmo registrador é identificado como AH (H aqui significa alto). E o primeiro byte (desse mesmo registrador) é identificado como AL (L aqui significa baixo). Olhando para o registro no canto inferior direito, os 64 bits são identificados como R15. Os primeiros 32 bits deste mesmo registrador são identificados como R15D. Os primeiros 16 bits deste mesmo registrador são identificados como R15W. E o primeiro byte é identificado como R15B. Os nomes dos outros registros (e sub-registros) são explicados de forma semelhante.
Existem algumas diferenças entre os µPs da Intel e da AMD. As informações nesta seção são para Intel.
Com o 6502 µP, o registro do contador de programa (não acessível diretamente) que contém a próxima instrução a ser executada tem 16 bits de largura. Aqui (x64), o contador do programa é chamado de ponteiro de instrução e tem 64 bits de largura. É rotulado como RIP. Isso significa que o x64 µP pode endereçar até 264 = 1,844674407 x 1019 (na verdade, 18.446.744.073.709.551.616) locais de bytes de memória. RIP não é um registro de uso geral.
O Stack Pointer Register ou RSP está entre os 16 registros de uso geral. Aponta para a última entrada da pilha na memória. Tal como acontece com 6502 µP, a pilha para x64 cresce para baixo. Com o x64, a pilha na RAM é usada para armazenar os endereços de retorno das sub-rotinas. Também é usado para armazenar o “espaço de sombra” (consulte a discussão a seguir).
O 6502 µP possui um registro de status do processador de 8 bits. O equivalente no x64 é chamado de registro RFLAGS. Este registrador armazena os flags que são utilizados para os resultados das operações e para controlar o processador (µP). Tem 64 bits de largura. Os 32 bits mais altos são reservados e não são usados atualmente. A tabela a seguir fornece os nomes, índices e significados dos bits comumente usados no registro RFLAGS:
| Tabela 6.31.1 Flags RFLAGS mais usados (Bits) |
|||
|---|---|---|---|
| Símbolo | Pedaço | Nome | Propósito |
| FC | 0 | Carregar | É definido se uma operação aritmética gera um carry ou empréstimo da parte mais significativa do resultado; limpo de outra forma. Este sinalizador indica uma condição de estouro para aritmética de números inteiros não assinados. Também é usado em aritmética de precisão múltipla. |
| PF | 2 | Paridade | É definido se o byte menos significativo do resultado contiver um número par de bits 1; limpo de outra forma. |
| DE | 4 | Ajustar | É definido se uma operação aritmética gera um carry ou empréstimo do bit 3 do resultado; limpo de outra forma. Este sinalizador é usado na aritmética decimal codificada em binário (BCD). |
| ZF | 6 | Zero | É definido se o resultado for zero; limpo de outra forma. |
| SF | 7 | Sinal | É definido se for igual ao bit mais significativo do resultado, que é o bit de sinal de um inteiro assinado (0 indica um valor positivo e 1 indica um valor negativo). |
| DE | onze | Transbordar | É definido se o resultado inteiro for um número positivo muito grande ou um número negativo muito pequeno (excluindo o bit de sinal) para caber no operando de destino; limpo de outra forma. Este sinalizador indica uma condição de overflow para a aritmética de número inteiro com sinal (complemento de dois). |
| DF | 10 | Direção | É definido se as instruções da cadeia de direção operarem (incremento ou decremento). |
| EU IA | vinte e um | Identificação | É definido se a mutabilidade denota a presença da instrução CPUID. |
Além dos dezoito registros de 64 bits indicados anteriormente, a arquitetura x64 µP possui oito registros de 80 bits de largura para aritmética de ponto flutuante. Esses oito registradores também podem ser usados como registradores MMX (consulte a discussão a seguir). Existem também dezesseis registros de 128 bits para XMM (consulte a discussão a seguir).
Isso não é tudo sobre registros. Existem mais registros x64 que são registros de segmento (a maioria não utilizados em x64), registros de controle, registros de gerenciamento de memória, registros de depuração, registros de virtualização, registros de desempenho que rastreiam todos os tipos de parâmetros internos (acertos/erros de cache, micro-operações executadas, tempo , e muito mais).
SIMD
SIMD significa Dados Múltiplos de Instrução Única. Isso significa que uma instrução em linguagem assembly pode atuar em vários dados ao mesmo tempo em um microprocessador. Considere a seguinte tabela:
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | |
| + | 9 | 10 | onze | 12 | 13 | 14 | quinze | 16 |
| = | 10 | 12 | 14 | 16 | 18 | vinte | 22 | 24 |
Nesta tabela, oito pares de números são somados em paralelo (na mesma duração) para dar oito respostas. Uma instrução em linguagem assembly pode fazer oito adições paralelas de números inteiros nos registradores MMX. Algo semelhante pode ser feito com os registradores XMM. Portanto, existem instruções MMX para números inteiros e instruções XMM para números flutuantes.
6.32 Mapa de memória e x64
Com o ponteiro de instrução (contador de programa) tendo 64 bits, isso significa que 264 = 1,844674407 x 1019 locais de bytes de memória podem ser endereçados. Em hexadecimal, a localização de bytes mais alta é FFFF,FFFF,FFFF,FFFF16. Nenhum computador comum hoje pode fornecer um espaço de memória tão grande (completo). Portanto, um mapa de memória adequado para o computador x64 é o seguinte:

Observe que a lacuna de 0000,8000,0000,000016 a FFFF,7FFF,FFFF,FFFF16 não possui locais de memória (sem bancos de memória RAM). Esta é uma diferença de FFFF,0000,0000,000116 que é bastante grande. A metade superior canônica contém o sistema operacional, enquanto a metade inferior canônica contém os programas do usuário (aplicativos) e os dados. O sistema operacional consiste em duas partes: uma pequena UEFI (BIOS) e uma grande parte que é carregada do disco rígido. O próximo capítulo fala mais sobre os sistemas operacionais modernos. Observe a semelhança com este mapa de memória e com o Commodore-64, quando 64 KB pode parecer muita memória.
Neste contexto, o sistema operacional é aproximadamente chamado de “kernel”. O kernel é semelhante ao Kernal do computador Commodore-64, mas possui muito mais sub-rotinas.
O endianness para x64 é little endian, o que significa que, para um local, o endereço inferior aponta para o byte de conteúdo inferior na memória.
6.33 Modos de endereçamento em linguagem assembly para x64
Os modos de endereçamento são as maneiras pelas quais uma instrução pode acessar os registradores µP e a memória (incluindo os registradores da porta interna). O x64 possui muitos modos de endereçamento, mas apenas os modos de endereçamento comumente usados são abordados aqui. A sintaxe geral para uma instrução aqui é:
destino do código de operação, origem
Os números decimais são escritos sem qualquer prefixo ou sufixo. Com o 6502, a fonte está implícita. O x64 possui mais códigos de operação que o 6502, mas alguns dos códigos de operação possuem os mesmos mnemônicos. As instruções x64 individuais têm comprimento variável e podem variar em tamanho de 1 a 15 bytes. Os modos de endereçamento comumente usados são os seguintes:
Modo de endereçamento imediato
Aqui, o operando de origem é um valor real e não um endereço ou rótulo. Exemplo (leia o comentário):
ADICIONE EAX, 14; adicione o decimal 14 ao EAX de 32 bits do RAX de 64 bits, a resposta permanece em EAX (destino)
Registre-se para registrar o modo de endereçamento
Exemplo:
ADICIONAR R8B, AL; adicione AL de 8 bits de RAX a R8B de R8 de 64 bits – as respostas permanecem em R8B (destino)
Modo de endereçamento indireto e indexado
O endereçamento indireto com o 6502 µP significa que a localização do endereço fornecido na instrução possui o endereço efetivo (ponteiro) da localização final. Algo semelhante acontece com x64. O endereçamento de índice com o 6502 µP significa que o conteúdo de um registrador µP é adicionado ao endereço fornecido na instrução para obter o endereço efetivo. Algo semelhante acontece com o x64. Além disso, com o x64, o conteúdo do registrador também pode ser multiplicado por 1 ou 2 ou 4 ou 8 antes de ser adicionado ao endereço fornecido. A instrução mov (cópia) do x64 pode combinar endereçamento indireto e indexado. Exemplo:
MOV R8W, 1234[8*RAX+RCX] ; mover palavra no endereço (8 x RAX + RCX) + 1234
Aqui, o R8W possui os primeiros 16 bits do R8. O endereço fornecido é 1234. O registro RAX possui um número de 64 bits que é multiplicado por 8. O resultado é adicionado ao conteúdo do registro RCX de 64 bits. Este segundo resultado é adicionado ao endereço fornecido, que é 1234, para obter o endereço efetivo. O número na localização do endereço efetivo é movido (copiado) para a primeira posição de 16 bits (R8W) do registrador R8, substituindo o que estiver lá. Observe o uso dos colchetes. Lembre-se de que uma palavra em x64 tem 16 bits de largura.
Endereçamento relativo RIP
Para o 6502 µP, o endereçamento relativo é usado somente com instruções de desvio. Lá, o único operando do opcode é um deslocamento que é adicionado ou subtraído ao conteúdo do Contador de Programa para o endereço de instrução efetivo (não o endereço de dados). Algo semelhante acontece com o x64 onde o Contador de Programa é chamado de Ponteiro de Instrução. A instrução com x64 não precisa ser apenas uma instrução de desvio. Um exemplo de endereçamento relativo ao RIP é:
MOV AL, [RIP]
AL do RAX possui um número assinado de 8 bits que é adicionado ou subtraído do conteúdo do RIP (ponteiro de instrução de 64 bits) para apontar para a próxima instrução. Observe que a origem e o destino são excepcionalmente trocados nesta instrução. Observe também o uso de colchetes que se refere ao conteúdo do RIP.
6.34 Instruções comumente usadas de x64
Na tabela a seguir, * significa diferentes sufixos possíveis de um subconjunto de opcodes:
| Tabela 6.34.1 Instruções comumente usadas em x64 |
|
|---|---|
| Código de operação | Significado |
| MOVIMENTOS | Mover (copiar) para/de/entre memória e registros |
| CMOV* | Vários movimentos condicionais |
| XCHG | Intercâmbio |
| BSWAP | Troca de bytes |
| EMPURRAR/POP | Uso de pilha |
| ADICIONAR/ADC | Adicionar/com transporte |
| SUB/SBC | Subtrair/com transporte |
| MUL/IMUL | Multiplicar/não assinado |
| DIV/IDIV | Dividir/não assinado |
| INC/DEZ | Incremento/Decremento |
| NEGRO | Negar |
| CMP | Comparar |
| E/OU/XOR/NÃO | Operações bit a bit |
| SHR/SAR | Deslocar para a direita lógico/aritmético |
| SHL/SAL | Deslocar para a esquerda lógico/aritmético |
| ROR/PAPEL | Girar para direita/esquerda |
| RCR/RCL | Gire para a direita/esquerda através da broca de transporte |
| BT/BTS/BTR | Teste de bits/e definir/e redefinir |
| JMP | Salto incondicional |
| JE/JNE/JC/JNC/J* | Saltar se for igual/diferente/carregar/não carregar/muitos outros |
| CAMINHAR/CAMINHAR/CAMINHAR | Loop com ECX |
| LIGAR/RET | Chamar sub-rotina/retorno |
| NÃO | Nenhuma operação |
| CPUID | Informações da CPU |
O x64 possui instruções de multiplicação e divisão. Possui circuitos de hardware de multiplicação e divisão em seu µP. O 6502 µP não possui circuitos de hardware de multiplicação e divisão. É mais rápido fazer a multiplicação e divisão por hardware do que por software (incluindo a mudança de bits).
Instruções de sequência
Existem várias instruções de string, mas a única a ser discutida aqui é a instrução MOVS (para mover string) para copiar uma string começando no endereço C000 H . Para começar no endereço C100 H , use a seguinte instrução:
MOVS [C100H], [C000H]
Observe o sufixo H para hexadecimal.
6.35 Loop em x64
O 6502 µP possui instruções de ramificação para loop. Uma instrução de desvio salta para um local de endereço que contém a nova instrução. A localização do endereço pode ser chamada de “loop”. O x64 possui instruções LOOP/LOOPE/LOOPNE para loop. Essas palavras reservadas em linguagem assembly não devem ser confundidas com o rótulo “loop” (sem as aspas). O comportamento é o seguinte:
LOOP diminui o ECX e verifica se o ECX não é zero. Se essa condição (zero) for atendida, ele salta para um rótulo especificado. Caso contrário, ele falhará (continue com o restante das instruções na discussão a seguir).
LOOPE decrementa ECX e verifica se ECX não é zero (pode ser 1, por exemplo) e ZF está definido (para 1). Se essas condições forem atendidas, ele salta para o rótulo. Caso contrário, ele falha.
LOOPNE decrementa ECX e verifica se ECX não é zero e ZF NÃO ESTÁ definido (ou seja, é zero). Se essas condições forem atendidas, ele salta para o rótulo. Caso contrário, ele falha.
Com x64, o registrador RCX ou suas subpartes, como ECX ou CX, contém o contador inteiro. Com as instruções LOOP, o contador normalmente faz a contagem regressiva, decrementando 1 a cada salto (loop). No segmento de código de loop a seguir, o número no registro EAX aumenta de 0 a 10 em dez iterações, enquanto o número no ECX diminui (diminui) 10 vezes (leia os comentários):
MOV EAX, 0 ;
MOVECX, 10; contagem regressiva 10 vezes por padrão, uma vez para cada iteração
rótulo:
INC EAX; incrementar EAX como corpo do loop
Rótulo LOOP; diminua EAX e, se EAX não for zero, execute novamente o corpo do loop de “label:”
A codificação do loop começa em “label:”. Observe o uso dos dois pontos. A codificação do loop termina com o “rótulo LOOP” que diz decremento EAX. Se o seu conteúdo não for zero, volte para a instrução após “label:” e execute novamente qualquer instrução (todas as instruções do corpo) que desça até o “LOOP label”. Observe que “rótulo” ainda pode ter outro nome.
6.36 Entrada/Saída de x64
Esta seção do capítulo trata do envio de dados para uma porta de saída (interna) ou do recebimento de dados de uma porta de entrada (interna). O chipset possui portas de oito bits. Quaisquer duas portas consecutivas de 8 bits podem ser tratadas como uma porta de 16 bits e quaisquer quatro portas consecutivas podem ser uma porta de 32 bits. Desta forma, o processador pode transferir 8, 16 ou 32 bits de ou para um dispositivo externo.
As informações podem ser transferidas entre o processador e uma porta interna de duas maneiras: usando o que é conhecido como entrada/saída mapeada em memória ou usando um espaço de endereço de entrada/saída separado. A E/S mapeada na memória é como acontece com o processador 6502, onde os endereços das portas fazem parte de todo o espaço da memória. Neste caso, ao enviar os dados para um determinado local de endereço, eles vão para uma porta e não para um banco de memória. As portas podem ter um espaço de endereço de E/S separado. Neste último caso, todos os bancos de memória têm seus endereços a partir de zero. Existe um intervalo de endereços separado de 0000H a FFFF16. Eles são usados pelas portas do chipset. A placa-mãe é programada para não confundir entre E/S mapeada em memória e espaço de endereço de E/S separado.
E/S mapeada em memória
Com isso, as portas são consideradas locais de memória, e os opcodes normais a serem utilizados entre a memória e o µP são utilizados para a transferência de dados entre o µP e as portas. Portanto, para mover um byte de uma porta no endereço F000H para o registrador µP RAX:EAX:AX:AL, faça o seguinte:
MOV AL, [F000H]
Uma string pode ser movida da memória para uma porta e vice-versa. Exemplo:
MOVS [F000H], [C000H] ; a origem é C000H e o destino é a porta em F000H.
Espaço de endereço de E/S separado
Com isso, devem ser utilizadas as instruções especiais de entrada e saída.
Transferindo itens individuais
O registro do processador para a transferência é RAX. Na verdade, é RAX:EAX para palavra dupla, RAX:EAX:AX para palavra e RAX:EAX:AX:AL para byte. Então, para transferir um byte de uma porta em FFF0h, para RAX:EAX:AX:AL, digite o seguinte:
EM AL, [FFF0H]
Para a transferência reversa, digite o seguinte:
FORA [FFF0H], AL
Portanto, para itens únicos, as instruções são IN e OUT. O endereço da porta também pode ser fornecido no registro RDX:EDX:DX.
Transferindo Strings
Uma string pode ser transferida da memória para uma porta do chipset e vice-versa. Para transferir uma string de uma porta no endereço FFF0H para a memória, comece em C100H, digite:
INS [ESI], [DX]
que tem o mesmo efeito que:
INS [EDI], [DX]
O programador deve colocar o endereço da porta de dois bytes FFF0H no registro RDX:EDX:Dx e deve colocar o endereço de dois bytes de C100H no registro RSI:ESI ou RDI:EDI. Para a transferência reversa, faça o seguinte:
INS [DX], [ESI]
que tem o mesmo efeito que:
INS [DX], [EDI]
6.37 A pilha em x64
Assim como o processador 6502, o processador x64 também possui uma pilha de RAM. A pilha para o x64 pode ser 2 16 = 65.536 bytes de comprimento ou pode ter 2 32 = 4.294.967.296 bytes de comprimento. Também cresce para baixo. Quando o conteúdo de um registrador é colocado na pilha, o número no ponteiro da pilha RSP diminui em 8. Lembre-se de que um endereço de memória para x64 tem 64 bits de largura. O valor no ponteiro da pilha no µP aponta para o próximo local na pilha na RAM. Quando o conteúdo de um registrador (ou um valor em um operando) é retirado da pilha para um registrador, o número no ponteiro da pilha RSP é aumentado em 8. O sistema operacional decide o tamanho da pilha e onde ela começa na RAM e cresce para baixo. Lembre-se de que uma pilha é uma estrutura Last-In-First-Out (LIFO) que cresce para baixo e diminui para cima neste caso.
Para enviar o conteúdo do registro µP RBX para a pilha, faça o seguinte:
PRESSIONE RBX
Para colocar a última entrada na pilha de volta no RBX, faça o seguinte:
POP RBX
6.38 Procedimento em x64
A sub-rotina no x64 é chamada de “procedimento”. A pilha é usada aqui mais do que para 6502 µP. A sintaxe para um procedimento x64 é:
nome_proc:
órgão de procedimento
…
certo
Antes de continuar, observe que os opcodes e rótulos para uma sub-rotina x64 (instruções em linguagem assembly em geral) não diferenciam maiúsculas de minúsculas. Isso é proc_name é igual a PROC_NAME. Assim como o 6502, o nome do procedimento (rótulo) começa no início de uma nova linha no editor de texto para a linguagem assembly. Isso é seguido por dois pontos e não por espaço e código de operação como no 6502. O corpo da sub-rotina segue, terminando com RET e não RTS como no 6502 µP. Tal como acontece com o 6502, cada instrução no corpo, incluindo RET, não começa no início da sua linha. Observe que um rótulo aqui pode ter mais de 8 caracteres. Para chamar este procedimento, acima ou abaixo do procedimento digitado, faça o seguinte:
CHAMAR proc_name
Com o 6502, o nome da etiqueta é apenas digitado para chamada. Porém, aqui é digitada a palavra reservada “CALL” ou “call”, seguida do nome do procedimento (sub-rotina) após um espaço.
Ao lidar com procedimentos, geralmente existem dois procedimentos. Um procedimento chama o outro. O procedimento que chama (possui a instrução de chamada) é chamado de “chamador”, e o procedimento que é chamado é chamado de “chamado”. Existe uma convenção (regras) a seguir.
As regras do chamador
O chamador deve seguir as seguintes regras ao invocar uma sub-rotina:
1. Antes de chamar uma sub-rotina, o chamador deve salvar na pilha o conteúdo de certos registros designados como salvos pelo chamador. Os registros salvos pelo chamador são R10, R11 e quaisquer registros nos quais os parâmetros sejam colocados (RDI, RSI, RDX, RCX, R8, R9). Se o conteúdo desses registros for preservado durante a chamada da sub-rotina, coloque-os na pilha em vez de salvá-los na RAM. Isso deve ser feito porque os registros devem ser usados pelo chamado para apagar o conteúdo anterior.
2. Se o procedimento for somar dois números, por exemplo, os dois números são os parâmetros a serem passados para a pilha. Para passar os parâmetros para a sub-rotina, coloque seis deles nos seguintes registros na ordem: RDI, RSI, RDX, RCX, R8, R9. Se houver mais de seis parâmetros na sub-rotina, coloque o restante na pilha na ordem inversa (ou seja, o último parâmetro primeiro). À medida que a pilha diminui, o primeiro dos parâmetros extras (na verdade o sétimo parâmetro) é armazenado no endereço mais baixo (esta inversão de parâmetros foi historicamente usada para permitir que as funções (sub-rotinas) fossem passadas com um número variável de parâmetros).
3. Para chamar a sub-rotina (procedimento), use a instrução call. Esta instrução coloca o endereço de retorno no topo dos parâmetros da pilha (posição mais baixa) e ramifica para o código da sub-rotina.
4. Após o retorno da sub-rotina (ou seja, imediatamente após a instrução de chamada), o chamador deve remover quaisquer parâmetros adicionais (além dos seis que estão armazenados nos registradores) da pilha. Isso restaura a pilha ao seu estado antes da chamada ser executada.
5. O chamador pode esperar encontrar o valor de retorno (endereço) da sub-rotina no registrador RAX.
6. O chamador restaura o conteúdo dos registros salvos pelo chamador (R10, R11 e qualquer outro registro de passagem de parâmetro) removendo-os da pilha. O chamador pode assumir que nenhum outro registro foi modificado pela sub-rotina.
Devido à forma como a convenção de chamada é estruturada, normalmente algumas (ou a maioria) dessas etapas não farão nenhuma alteração na pilha. Por exemplo, se houver seis ou menos parâmetros, nada será colocado na pilha nessa etapa. Da mesma forma, os programadores (e compiladores) normalmente mantêm os resultados que lhes interessam fora dos registros salvos pelo chamador nas etapas 1 e 6 para evitar pushes e pops excessivos.
Existem duas outras maneiras de passar parâmetros para uma sub-rotina, mas elas não serão abordadas neste curso de carreira online. Um deles usa a própria pilha em vez dos registradores de uso geral.
As regras do chamado
A definição da sub-rotina chamada deverá obedecer às seguintes regras:
1. Aloque as variáveis locais (variáveis que são desenvolvidas dentro do procedimento) utilizando os registradores ou abrindo espaço na pilha. Lembre-se de que a pilha cresce para baixo. Portanto, para liberar espaço no topo da pilha, o ponteiro da pilha deve ser decrementado. A quantidade pela qual o ponteiro da pilha é decrementado depende do número necessário de variáveis locais. Por exemplo, se um local float e um local long (12 bytes no total) forem necessários, o ponteiro da pilha precisará ser decrementado em 12 para liberar espaço para essas variáveis locais. Em uma linguagem de alto nível como C, isso significa declarar as variáveis sem atribuir (inicializar) os valores.
2. Em seguida, os valores de quaisquer registros designados como salvos pelo chamador (registros de uso geral não salvos pelo chamador) usados pela função devem ser salvos. Para salvar os registros, coloque-os na pilha. Os registros salvos pelo receptor são RBX, RBP e R12 a R15 (RSP também é preservado pela convenção de chamada, mas não precisa ser colocado na pilha durante esta etapa).
Depois que essas três ações forem executadas, a operação real da sub-rotina poderá prosseguir. Quando a sub-rotina estiver pronta para retornar, as regras da convenção de chamada continuam.
3. Quando a sub-rotina estiver concluída, o valor de retorno da sub-rotina deverá ser colocado em RAX, se ainda não estiver lá.
4. A sub-rotina deve restaurar os valores antigos de quaisquer registros salvos pelo receptor (RBX, RBP e R12 a R15) que foram modificados. O conteúdo do registrador é restaurado retirando-o da pilha. Observe que os registros devem ser exibidos na ordem inversa em que foram enviados.
5. A seguir, desalocamos as variáveis locais. A maneira mais fácil de fazer isso é adicionar ao RSP o mesmo valor que foi subtraído no passo 1.
6. Finalmente, retornamos ao chamador executando uma instrução ret. Esta instrução encontrará e removerá o endereço de retorno apropriado da pilha.
Um exemplo do corpo de uma sub-rotina chamadora para chamar outra sub-rotina que é “myFunc” é o seguinte (leia os comentários):
; Quer chamar uma função “myFunc” que leva três
; parâmetro inteiro. O primeiro parâmetro está em RAX.
; O segundo parâmetro é a constante 456. Terceiro
; o parâmetro está no local da memória ”variável”
empurre rdi; rdi será um parâmetro, então salve-o
; long retVal = minhaFunc(x, 456, z);
mov rdi , rax ; coloque o primeiro parâmetro no RDI
mov rsi, 456; coloque o segundo parâmetro no RSI
mov rdx , [variável] ; coloque o terceiro parâmetro no RDX
chame minhaFunc ; chame a função
pop rdi; restaurar o valor RDI salvo
; o valor de retorno de myFunc agora está disponível no RAX
Um exemplo de função callee (myFunc) é (leia os comentários):
minhaFunc :
; ∗∗∗ Prólogo de sub-rotina padrão ∗∗∗
sub rsp, 8 ; espaço para uma variável local de 64 bits (resultado) usando o opcode “sub”
empurre rbx; salvar registros de salvamento de callee
empurre rbp; ambos serão usados por myFunc
; ∗∗∗ Sub-rotina Corpo ∗∗∗
mov rax, rdi; parâmetro 1 para RAX
mov rbp, rsi; parâmetro 2 para RBP
mov rbx, rdx; parâmetro 3 para rb x
mov [rsp + 1 6], rbx; coloque rbx na variável local
adicione [rsp + 1 6], rbp; adicione rbp na variável local
mov rax, [rsp +16]; mov conteúdo da variável local para RAX
; (valor de retorno/resultado final)
; ∗∗∗ Epílogo de sub-rotina padrão ∗∗∗
pop rbp; recuperar registros salvos do receptor
pop rbx; reverso de quando empurrado
adicione rsp, 8; desalocar variáveis locais. 8 significa 8 bytes
ret; pop o valor superior da pilha, pule para lá
6.39 Interrupções e exceções para x64
O processador fornece dois mecanismos para interromper a execução do programa, interrupções e exceções:
- Uma interrupção é um evento assíncrono (pode acontecer a qualquer momento) que normalmente é acionado por um dispositivo de E/S.
- Uma exceção é um evento síncrono (acontece conforme o código é executado, pré-programado, com base em alguma ocorrência) que é gerado quando o processador detecta uma ou mais condições predefinidas durante a execução de uma instrução. Três classes de exceções são especificadas: falhas, armadilhas e abortos.
O processador responde a interrupções e exceções essencialmente da mesma maneira. Quando uma interrupção ou exceção é sinalizada, o processador interrompe a execução do programa ou tarefa atual e muda para um procedimento manipulador escrito especificamente para tratar a condição de interrupção ou exceção. O processador acessa o procedimento manipulador por meio de uma entrada na Interrupt Descriptor Table (IDT). Quando o manipulador tiver concluído o tratamento da interrupção ou exceção, o controle do programa será retornado ao programa ou tarefa interrompida.
O sistema operacional, os drivers executivos e/ou de dispositivo normalmente lidam com as interrupções e exceções independentemente dos programas aplicativos ou tarefas. Os programas aplicativos podem, entretanto, acessar os manipuladores de interrupções e exceções que estão incorporados em um sistema operacional ou executá-lo através de chamadas em linguagem assembly.
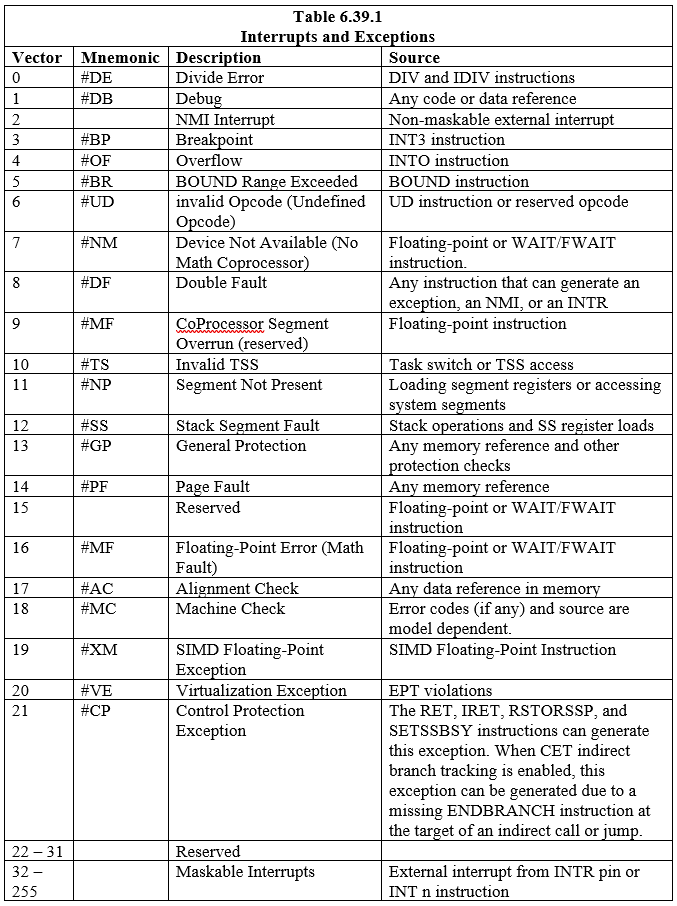
São definidas dezoito (18) interrupções e exceções predefinidas, associadas às entradas no IDT. Duzentas e vinte e quatro (224) interrupções definidas pelo usuário também podem ser feitas e associadas à tabela. Cada interrupção e exceção no IDT é identificada com um número chamado “vetor”. A Tabela 6.39.1 lista as interrupções e exceções com entradas no IDT e seus respectivos vetores. Os vetores 0 a 8, 10 a 14 e 16 a 19 são as interrupções e exceções predefinidas. Os vetores 32 a 255 são para interrupções definidas por software (usuário), que são para interrupções de software ou interrupções de hardware mascaráveis.
Quando o processador detecta uma interrupção ou exceção, ele executa uma das seguintes ações:
- Execute uma chamada implícita para um procedimento manipulador
- Execute uma chamada implícita para uma tarefa de manipulador
6.4 Noções básicas de arquitetura de computador ARM de 64 bits
As arquiteturas ARM definem uma família de processadores RISC adequados para uso em uma ampla variedade de aplicações. ARM é uma arquitetura de carregamento/armazenamento que requer que os dados sejam carregados da memória para um registro antes que qualquer processamento, como uma operação ALU (Unidade Lógica Aritmética), possa ocorrer com ele. Uma instrução subsequente armazena o resultado de volta na memória. Embora isso possa parecer um retrocesso em relação às arquiteturas x86 e x64, que operam diretamente nos operandos da memória em uma única instrução (usando registradores do processador, é claro), a abordagem carregar/armazenar, na prática, permite diversas operações sequenciais. deve ser executado em alta velocidade em um operando, uma vez carregado em um dos muitos registradores do processador. Os processadores ARM têm a opção de little endianness ou big endianness. A configuração padrão do ARM 64 é little-endian, que é a configuração comumente usada pelos sistemas operacionais. A arquitetura ARM de 64 bits é moderna e está preparada para substituir a arquitetura ARM de 32 bits.
Observação : Cada instrução para o ARM µP de 64 bits tem 4 bytes (32 bits) de comprimento.
6.41 O conjunto de registros ARM de 64 bits
Existem 31 registros de uso geral de 64 bits para o ARM µP de 64 bits. O diagrama a seguir mostra os registradores de uso geral e alguns registradores importantes:
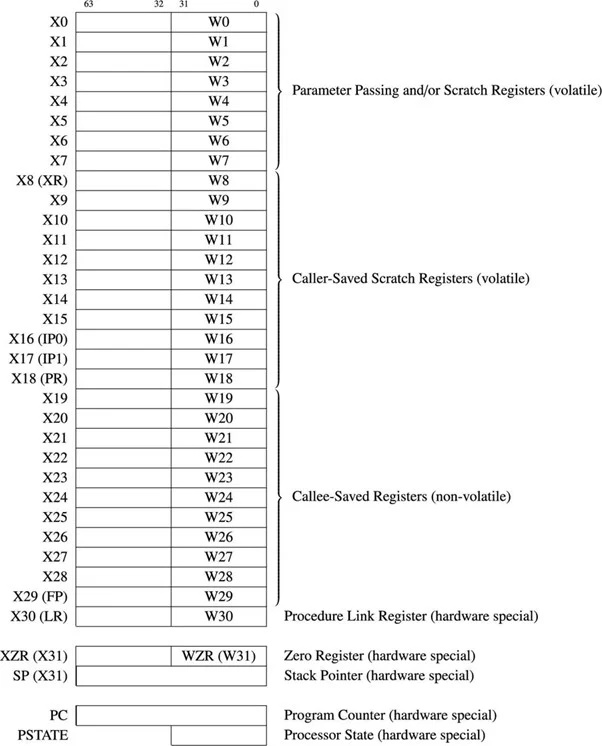
Fig.4.11.1 Uso geral de 64 bits e alguns registros importantes
Os registradores de uso geral são chamados de X0 a X30. A primeira parte de 32 bits de cada registro é chamada de W0 a W30. Quando a diferença entre 32 bits e 64 bits não é enfatizada, o prefixo “R” é usado. Por exemplo, R14 refere-se a W14 ou X14.
O 6502 µP possui um contador de programa de 16 bits e pode endereçar 2 16 localizações de bytes de memória. O ARM µP de 64 bits possui um contador de programa de 64 bits e pode endereçar até 2 64 = 1,844674407 x 1019 (na verdade 18.446.744.073.709.551.616) locais de bytes de memória. O contador do programa contém o endereço da próxima instrução a ser executada. O comprimento da instrução do ARM64 ou AArch64 é normalmente de quatro bytes. O processador incrementa automaticamente esse registrador em quatro após cada instrução ser buscada na memória.
O registro Stack Pointer ou SP não está entre os 31 registros de uso geral. O ponteiro da pilha de qualquer arquitetura aponta para a última entrada da pilha na memória. Para o ARM-64, a pilha cresce para baixo.
O 6502 µP possui um registro de status do processador de 8 bits. O equivalente no ARM64 é chamado de registro PSTATE. Este registrador armazena os flags que são utilizados para os resultados das operações e para controlar o processador (µP). Tem 32 bits de largura. A tabela a seguir fornece os nomes, índices e significados dos bits comumente usados no registro PSTATE:
| Tabela 6.41.1 Sinalizadores PSTATE mais usados (Bits) |
||
|---|---|---|
| Símbolo | Pedaço | Propósito |
| M | 0-3 | Modo: O nível de privilégio de execução atual (USR, SVC e assim por diante). |
| T | 4 | Thumb: É definido se o conjunto de instruções T32 (Thumb) estiver ativo. Se estiver claro, o conjunto de instruções ARM está ativo. O código do usuário pode definir e limpar esse bit. |
| E | 9 | Endianness: Definir este bit habilita o modo big-endian. Se estiver claro, o modo little-endian está ativo. O padrão é o modo little-endian. |
| P | 27 | Sinalizador de saturação cumulativa: É definido se, em algum ponto de uma série de operações, ocorrer um estouro ou saturação |
| EM | 28 | Sinalizador de overflow: É definido se a operação resultou em um overflow assinado. |
| C | 29 | Sinalizador de carry: indica se a adição produziu um carry ou a subtração produziu um empréstimo. |
| COM | 30 | Flag Zero: É definido se o resultado de uma operação for zero. |
| N | 31 | Sinalizador negativo: É definido se o resultado de uma operação for negativo. |
O ARM-64 µP possui muitos outros registros.
SIMD
SIMD significa Instrução Única, Dados Múltiplos. Isso significa que uma instrução em linguagem assembly pode atuar em vários dados ao mesmo tempo em um microprocessador. Existem trinta e dois registradores de 128 bits para uso com SIMD e operações de ponto flutuante.
6.42 Mapeamento de Memória
RAM e DRAM são memórias de acesso aleatório. A DRAM é mais lenta em operação que a RAM. DRAM é mais barato que RAM. Se houver mais de 32 gigabytes (GB) de DRAM contínua na memória, haverá mais problemas de gerenciamento de memória: 32 GB = 32 x 1024 x 1024 x 1024 bytes. Para todo um espaço de memória muito maior que 32 GB, a DRAM acima de 32 GB deve ser intercalada com RAMs para melhor gerenciamento de memória. Para entender o mapa de memória ARM-64, você deve primeiro entender o mapa de memória de 4 GB para a Unidade Central de Processamento (CPU) ARM de 32 bits. CPU significa µP. Para um computador de 32 bits, o espaço máximo de memória endereçável é 2 32 = 4x2 10 x 2 10 x 2 10 = 4 x 1024 x 1024 x 1024 = 4.294.967.296 = 4 GB.
Mapa de memória ARM de 32 bits
O mapa de memória para um ARM de 32 bits é:

Para um computador de 32 bits, o tamanho máximo de toda a memória é 4 GB. Do endereço de 0 GB ao endereço de 1 GB estão o sistema operacional ROM, a RAM e os locais de E/S. Toda a ideia de ROM OS, RAM e endereços de E/S é semelhante à situação do Commodore-64 com uma possível CPU 6502. A ROM do sistema operacional do Commodore-64 está no limite superior do espaço de memória. O ROM OS aqui é muito maior que o do Commodore-64 e está no início de todo o espaço de endereço da memória. Quando comparado a outros computadores modernos, o ROM OS aqui é completo, no sentido de que é comparável à quantidade de SO em seus discos rígidos. Existem duas razões principais para ter o sistema operacional nos circuitos integrados ROM: 1) CPUs ARM são usadas principalmente em dispositivos pequenos como smartphones. Muitos discos rígidos são maiores que smartphones e outros dispositivos pequenos, 2) por segurança. Quando o sistema operacional está na memória somente leitura, ele não pode ser corrompido (partes sobrescritas) por hackers. As seções de RAM e seções de entrada/saída também são muito grandes em comparação com as do Commodore-64.
Quando a energia é ligada com o sistema operacional ROM de 32 bits, o sistema operacional deve iniciar (inicializar a partir) do endereço 0x00000000 ou do endereço 0xFFFF0000 se o HiVECs estiver habilitado. Assim, quando a energia é ligada após a fase de reset, o hardware da CPU carrega 0x00000000 ou 0xFFFF0000 no Contador de Programa. O prefixo “0x” significa hexadecimal. O endereço de inicialização das CPUs ARMv8 de 64 bits é uma implementação definida. No entanto, o autor aconselha o engenheiro de computação a começar em 0x00000000 ou 0xFFFF0000 para fins de compatibilidade com versões anteriores.
De 1 GB a 2 GB é a entrada/saída mapeada. Há uma diferença entre a E/S mapeada e apenas a E/S encontrada entre 0 GB e 1 GB. Com E/S, o endereço de cada porta é fixo como no Commodore-64. Com E/S mapeadas, o endereço de cada porta não é necessariamente o mesmo para cada operação do computador (dinâmico).
De 2 GB a 4 GB é DRAM. Esta é a RAM esperada (ou usual). DRAM significa RAM Dinâmica, não no sentido de uma mudança de endereço durante a operação do computador, mas no sentido de que o valor de cada célula na RAM física deve ser atualizado a cada pulso de clock.
Observação :
- De 0x0000.0000 a 0x0000,FFFF é a ROM do sistema operacional.
- De 0x0001.0000 a 0x3FFF,FFFF, pode haver mais ROM, depois RAM e, em seguida, alguma E/S.
- De 0x4000,0000 a 0x7FFF,FFFF, uma E/S adicional e/ou E/S mapeada é permitida.
- De 0x8000.0000 a 0xFFFF,FFFF é a DRAM esperada.
Isto significa que a DRAM esperada não precisa começar no limite de memória de 2 GB, na prática. Por que o programador deveria respeitar os limites ideais quando não há bancos de RAM físicos suficientes encaixados na placa-mãe? Isso ocorre porque o cliente não tem dinheiro suficiente para todos os bancos de RAM.
Mapa de memória ARM de 36 bits
Para um computador ARM de 64 bits, todos os 32 bits são usados para endereçar toda a memória. Para um computador ARM de 64 bits, os primeiros 36 bits podem ser usados para endereçar toda a memória que, neste caso, é 2 36 = 68.719.476.736 = 64 GB. Isso já é muita memória. Os computadores comuns de hoje não precisam dessa quantidade de memória. Isso ainda não atinge a faixa máxima de memória que pode ser acessada por 64 bits. O mapa de memória de 36 bits para a CPU ARM é:
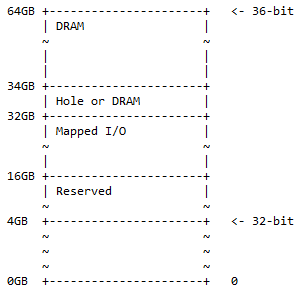
Do endereço de 0 GB ao endereço de 4 GB está o mapa de memória de 32 bits. “Reservado” significa não utilizado e é mantido para uso futuro. Não é necessário que haja bancos de memória física encaixados na placa-mãe para esse espaço. Aqui, a DRAM e a E/S mapeada têm os mesmos significados do mapa de memória de 32 bits.
A seguinte situação pode ser encontrada na prática:
- 0x1 0000 0000 – 0x3 FFFF FFFF; reservado. 12 GB de espaço de endereço são reservados para uso futuro.
- 0x4 0000 0000 – 0x7 FFFF FFFF; E/S mapeada. 16 GB de espaço de endereço estão disponíveis para E/S mapeadas dinamicamente.
- 0x8 0000 0000 – 0x8 7FFF FFFF FFFF; Buraco ou DRAM. 2 GB de espaço de endereço podem conter um dos seguintes itens:
- Orifício para ativar o particionamento do dispositivo DRAM (conforme descrito na discussão a seguir).
- DRAM.
- 0x8 8000 0000 – 0xF FFFF FFFF; DRAM. 30 GB de espaço de endereço para DRAM.
Este mapa de memória é um superconjunto do mapa de endereços de 32 bits, com o espaço adicional sendo dividido como 50% DRAM (1/2) com um furo opcional nele e 25% de espaço de E/S mapeado e espaço reservado (1/4 ). Os 25% restantes (1/4) são para o mapa de memória de 32 bits ½ + ¼ + ¼ = 1.
Observação : De 32 bits a 360 bits há uma adição de 4 bits ao lado mais significativo de 36 bits.
Mapa de memória de 40 bits
O mapa de endereços de 40 bits é um superconjunto do mapa de endereços de 36 bits e segue o mesmo padrão de 50% de DRAM de um buraco opcional nele, 25% de espaço de E/S mapeado e espaço reservado, e o restante dos 25% espaço para o mapa de memória anterior (36 bits). O diagrama do mapa de memória é:
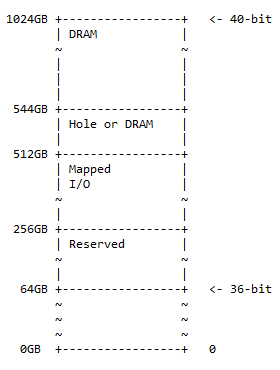
O tamanho do buraco é 544 – 512 = 32GB. A seguinte situação pode ser encontrada na prática:
- 0x10 0000 0000 – 0x3F FFFF FFFF; reservado. 192 GB de espaço de endereço são reservados para uso futuro.
- 0x40 0000 0000 – 0x7F FFFF FFFF; mapeado. E/S 256 GB de espaço de endereço estão disponíveis para E/S mapeada dinamicamente.
- 0x80 0000 0000 – 0x87 FFFF FFFF; buraco ou DRAM. 32 GB de espaço de endereço podem conter um dos seguintes itens:
- Orifício para ativar o particionamento do dispositivo DRAM (conforme descrito na discussão a seguir)
- DRAM
- 0x88 0000 0000 – 0xFF FFFF FFFF; DRAM. 480 GB de espaço de endereço para DRAM.
Observação : De 36 bits a 40 bits há uma adição de 4 bits ao lado mais significativo de 36 bits.
Buraco DRAM
No mapa de memória além de 32 bits, é um DRAM Hole ou uma continuação da DRAM de cima para baixo. Quando é um buraco, deve ser apreciado da seguinte forma: O buraco DRAM fornece uma maneira de particionar um grande dispositivo DRAM em vários intervalos de endereços. O furo DRAM opcional é proposto no início do limite superior de endereço DRAM. Isso permite um esquema de decodificação simplificado ao particionar um dispositivo DRAM de grande capacidade na região de endereço físico inferior.
Por exemplo, uma parte DRAM de 64 GB é subdividida em três regiões com os deslocamentos de endereço realizados por uma simples subtração nos bits de endereço de ordem superior como segue:
| Tabela 6.42.1 Exemplo de particionamento DRAM de 64 GB com furos |
|||
|---|---|---|---|
| Endereços físicos em SoC | Desvio | Endereço DRAM interno | |
| 2 GBytes (mapa de 32 bits) | 0x00 8000 0000 – 0x00 FFFF FFFF | -0x00 8.000.0000 | 0x00 0000 0000 – 0x00 7FFF FFFF |
| 30 GBytes (mapa de 36 bits) | 0x08 8000 0000 – 0x0F FFFF FFFF | -0x08 0000 0000 | 0x00 8000 0000 – 0x07 FFFF FFFF |
| 32 GBytes (mapa de 40 bits) | 0x88 0000 0000 – 0x8F FFFF FFFF | -0x80 0000 0000 | 0x08 0000 0000 – 0x0F FFFF FFFF |
Mapas de memória endereçados de 44 e 48 bits propostos para CPUs ARM
Suponha que um computador pessoal tenha 1.024 GB (= 1 TB) de memória; isso é muita memória. E assim, os mapas de memória endereçada de 44 e 48 bits para CPUs ARM de 16 TB e 256 TB, respectivamente, são apenas propostas para necessidades futuras de computadores. Na verdade, essas propostas para CPUs ARM seguem a mesma divisão de memória por proporção dos mapas de memória anteriores. Ou seja: 50% de DRAM com um furo opcional, 25% de espaço de E/S mapeado e espaço reservado e o restante dos 25% de espaço para o mapa de memória anterior.
Os mapas de memória endereçada de 52, 56, 60 e 64 bits ainda serão propostos para o ARM de 64 bits em um futuro distante. Se os cientistas da época ainda acharem útil o particionamento 50:25:25 de todo o espaço de memória, eles manterão a proporção.
Observação : SoC significa System-on-Chip, que se refere a circuitos no chip µP que de outra forma não existiriam.
SRAM ou Static Random Access Memory é mais rápida que a DRAM mais tradicional, mas requer mais área de silício. SRAM não requer atualização. O leitor pode imaginar RAM como SRAM.
6.43 Modos de endereçamento em linguagem assembly para ARM 64
ARM é uma arquitetura de carregamento/armazenamento que requer que os dados sejam carregados da memória para um registro do processador antes que qualquer processamento, como uma operação lógica aritmética, possa ocorrer com ele. Uma instrução subsequente armazena o resultado de volta na memória. Embora isso possa parecer um retrocesso em relação às arquiteturas x86 e suas arquiteturas x64 subsequentes, que operam diretamente nos operandos da memória em uma única instrução, na prática, a abordagem carregar/armazenar permite que diversas operações sequenciais sejam executadas em alta velocidade. um operando, uma vez carregado em um dos muitos registradores do processador.
O formato da linguagem assembly ARM tem semelhanças e diferenças com a série x64 (x86).
- Desvio : Uma constante assinada pode ser adicionada ao registrador base. O deslocamento é digitado como parte da instrução. Por exemplo: ldr x0, [rx, #10] carrega r0 com a palavra no endereço r1+10.
- Registro : Um incremento não assinado armazenado em um registro pode ser adicionado ou subtraído do valor em um registro base. Por exemplo: ldr r0, [x1, x2] carrega r0 com a palavra no endereço x1+x2. Qualquer um dos registradores pode ser considerado o registrador base.
- Registro escalonado : Um incremento em um registro é deslocado para a esquerda ou para a direita por um número especificado de posições de bits antes de ser adicionado ou subtraído do valor do registro base. Por exemplo: ldr x0, [x1, x2, lsl #3] carrega r0 com a palavra no endereço r1+(r2×8). O deslocamento pode ser um deslocamento lógico para a esquerda ou para a direita (lsl ou lsr) que insere zero bits nas posições de bits desocupadas ou um deslocamento aritmético para a direita (asr) que replica o bit de sinal nas posições desocupadas.
Quando dois operandos estão envolvidos, o destino vem antes (à esquerda) da origem (há algumas exceções a isso). Os opcodes para a linguagem assembly ARM não diferenciam maiúsculas de minúsculas.
Modo de endereçamento ARM64 imediato
Exemplo:
movimento r0, #0xFF000000; Carregue o valor de 32 bits FF000000h em r0
Um valor decimal não contém 0x, mas ainda é precedido por #.
Cadastre-se direto
Exemplo:
movimento x0, x1; Copiar x1 para x0
Cadastrar Indireto
Exemplo:
string x0, [x3]; Armazene x0 no endereço em x3
Cadastrar Indireto com Offset
Exemplos:
ldr x0, [x1, #32] ; Carregue r0 com o valor no endereço [r1+32]; r1 é o registrador base
string x0, [x1, #4]; Armazene r0 no endereço [r1+4]; r1 é o registrador base; os números são de base 10
Registrar Indireto com Offset (Pré-incrementado)
Exemplos:
ldr x0, [x1, #32]! ; Carregue r0 com [r1+32] e atualize r1 para (r1+32)
str x0, [x1, #4]! ; Armazene r0 em [r1+4] e atualize r1 em (r1+4)
Observe o uso do “!” símbolo.
Registrar Indireto com Offset (Pós-incrementado)
Exemplos:
ldr x0, [x1], #32; Carregue [x1] para x0 e atualize x1 para (x1+32)
string x0, [x1], #4; Armazene x0 em [x1] e atualize x1 em (x1+4)
Registro Duplo Indireto
O endereço do operando é a soma de um registrador base e um registrador de incremento. Os nomes dos registros estão entre colchetes.
Exemplos:
ldr x0, [x1, x2] ; Carregue x0 com [x1+x2]
str x0, [rx, x2] ; Armazene x0 em [x1+x2]
Modo de endereçamento relativo
No modo de endereçamento relativo, a instrução efetiva é a próxima instrução no Contador de Programa, mais um índice. O índice pode ser positivo ou negativo.
Exemplo:
ldr x0, [pc, #24]
Isso significa o registro de carga X0 com a palavra apontada pelo conteúdo do PC mais 24.
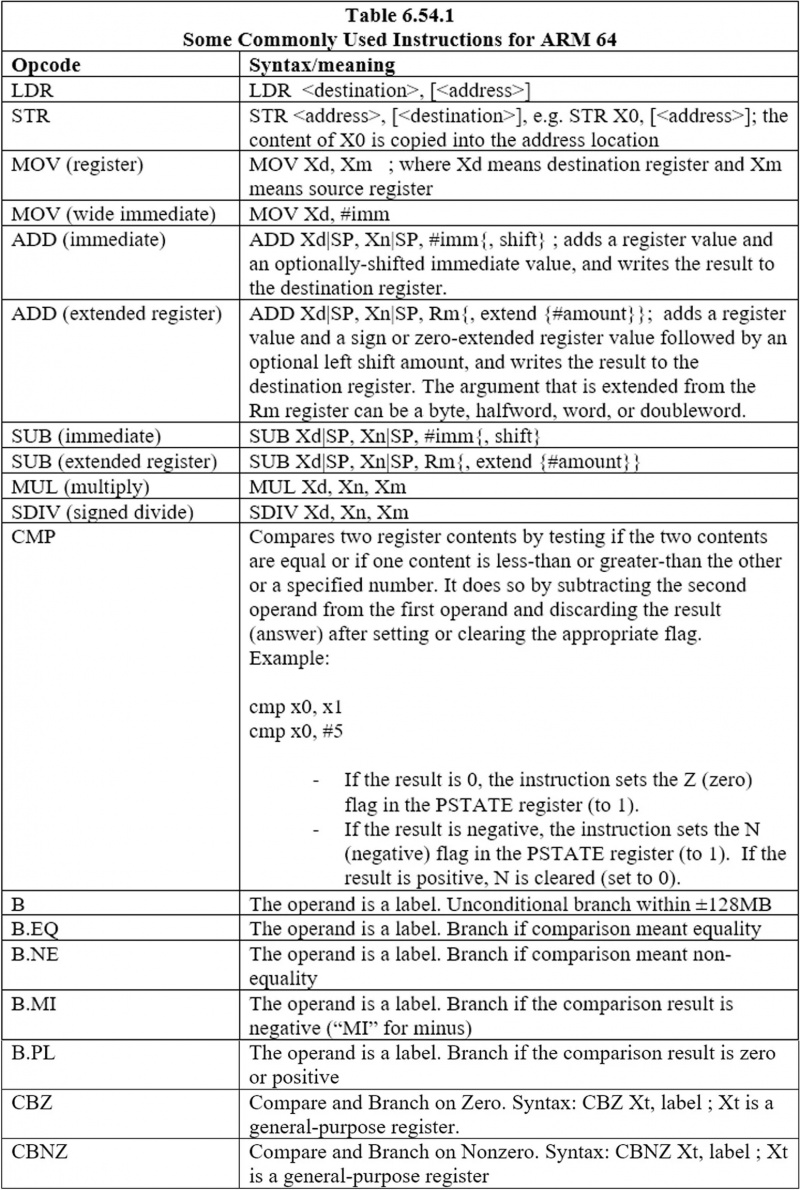
6.44 Algumas instruções comumente usadas para ARM 64
Aqui estão as instruções comumente usadas:
6.45 Loop
Ilustração
O código a seguir continua adicionando o valor no registro X10 ao valor em X9 até que o valor em X8 seja zero. Suponha que todos os valores sejam inteiros. O valor em X8 é subtraído por 1 em cada iteração:
laço:
CBZ X8, pule
ADICIONE X9, X9, X10; o primeiro X9 é o destino e o segundo X9 é a origem
SUB X8, X8, #1; o primeiro X8 é o destino e o segundo X8 é a origem
Ciclo B
pular:
Assim como no 6502 µP e no X64 µP, o rótulo no ARM 64 µP começa no início da linha. O restante das instruções começa em alguns espaços após o início da linha. Com x64 e ARM 64, o rótulo é seguido por dois pontos e uma nova linha. Enquanto no 6502, o rótulo é seguido por uma instrução após um espaço. No código anterior, a primeira instrução que é “CBZ X8, skip” significa que se o valor em X8 for zero, continue no rótulo “skip:”, pulando as instruções intermediárias e continuando com o restante das instruções abaixo 'pular:'. “B loop” é um salto incondicional para o rótulo “loop”. Qualquer outro nome de rótulo pode ser usado no lugar de “loop”.
Assim como no 6502 µP, use as instruções de ramificação para fazer um loop com o ARM 64.
6.46 Entrada/Saída ARM 64
Todos os periféricos ARM (portas internas) são mapeados na memória. Isso significa que a interface de programação é um conjunto de registros endereçados à memória (portas internas). O endereço de tal registro é um deslocamento de um endereço base de memória específico. Isso é semelhante a como o 6502 faz a entrada/saída. O ARM não tem a opção de espaço de endereço de E/S separado.
6.47 Pilha de ARM 64
O ARM 64 possui uma pilha de memória (RAM) de forma semelhante ao 6502 e x64. No entanto, com o ARM64, não há opcode push ou pop. A pilha no ARM 64 também cresce para baixo. O endereço no ponteiro da pilha aponta logo após o último byte do último valor colocado na pilha.
A razão pela qual não há código de operação pop ou push genérico para o ARM64 é que o ARM 64 gerencia sua pilha em grupos de 16 bytes consecutivos. No entanto, os valores existem em grupos de bytes de um byte, dois bytes, quatro bytes e 8 bytes. Portanto, um valor pode ser colocado na pilha e o restante dos locais (localizações de bytes) para compensar 16 bytes são preenchidos com bytes fictícios. Isso tem a desvantagem de desperdiçar memória. Uma solução melhor é preencher o local de 16 bytes com valores menores e ter algum código escrito pelo programador que rastreie de onde vêm os valores no local de 16 bytes (registros). Este código extra também é necessário para recuperar os valores. Uma alternativa para isso é preencher dois registradores de uso geral de 8 bytes com valores diferentes e, em seguida, enviar o conteúdo dos dois registradores de 8 bytes para uma pilha. Um código extra ainda é necessário aqui para rastrear os pequenos valores específicos que vão para a pilha e saem dela.
O código a seguir armazena quatro dados de 4 bytes na pilha:
str w0, [sp, #-4]!
str w1, [sp, #-8]!
str w2, [sp, #-12]!
str w3, [sp, #-16]!
Os primeiros quatro bytes (w) dos registradores – x0, x1, x2 e x3 – são enviados para locais de 16 bytes consecutivos na pilha. Observe o uso de “str” e não de “push”. Observe o símbolo de exclamação no final de cada instrução. Como a pilha de memória cresce para baixo, o primeiro valor de quatro bytes começa em uma posição menos quatro bytes abaixo da posição anterior do ponteiro da pilha. O restante dos valores de quatro bytes segue, diminuindo. O segmento de código a seguir fará o equivalente correto (e em ordem) de estourar os quatro bytes:
ldr w3, [sp], #0
ldr w2, [sp], #4
ldr w1, [sp], #8
ldr w0, [sp], #12
Observe o uso do opcode ldr em vez de pop. Observe também que o símbolo de exclamação não é usado aqui.
Todos os bytes em X0 (8 bytes) e X1 (8 bytes) podem ser enviados para o local de 16 bytes na pilha da seguinte forma:
ponto x0, x1, [sp, #-16]! ; 8 + 8 = 16
Neste caso, os registros x2 (w2) e x3 (w3) não são necessários. Todos os bytes desejados estão nos registradores X0 e X2. Observe o opcode stp para armazenar os pares de conteúdo de registro na RAM. Observe também o símbolo de exclamação. O equivalente pop é:
ldp x0, x1, [sp], #0
Não há sinal de exclamação para esta instrução. Observe o opcode LDP em vez de LDR para carregar dois locais de dados consecutivos da memória para dois registradores µP. Lembre-se também de que copiar da memória para um registro µP é carregar, não deve ser confundido com carregar um arquivo do disco para a RAM, e copiar de um registro µP para a RAM é armazenar.
6.48 Subrotina
Uma sub-rotina é um bloco de código que executa uma tarefa, opcionalmente baseada em alguns argumentos e, opcionalmente, retorna um resultado. Por convenção, os registradores R0 a R3 (quatro registradores) são usados para passar os argumentos (parâmetros) para uma sub-rotina, e R0 é usado para passar um resultado de volta ao chamador. Uma sub-rotina que precisa de mais de 4 entradas usa a pilha para as entradas adicionais. Para chamar uma sub-rotina, use o link ou a instrução de desvio condicional. A sintaxe para a instrução de link é:
Etiqueta BL
Onde BL é o opcode e label representa o início (endereço) da sub-rotina. Esta ramificação é incondicional, para frente ou para trás em 128 MB. A sintaxe para a instrução de desvio condicional é:
Rótulo B.cond
Onde cond é a condição, por exemplo, eq (igual) ou ne (diferente). O programa a seguir possui a sub-rotina doadd que soma os valores de dois argumentos e retorna um resultado em R0:
Subrota AREA, CODE, READONLY ; Nomeie este bloco de código
ENTRADA; Marque a primeira instrução a ser executada
iniciar MOV r0, #10 ; Configurar parâmetros
MOV r1, #3
BL doadd ; Chamar sub-rotina
parar MOV r0, #0x18 ; anjo_SWIreason_ReportException
LDRr1, =0x20026; ADP_Stopped_ApplicationExit
SVC#0x123456; Semihospedagem ARM (anteriormente SWI)
doadd ADD r0, r0, r1 ; Código de subrotina
BXlr; Retorno da sub-rotina
;
FIM ; Marcar o fim do arquivo
Os números a serem adicionados são o decimal 10 e o decimal 3. As duas primeiras linhas deste bloco de código (programa) serão explicadas posteriormente. As próximas três linhas enviam 10 para o registro R0 e 3 para o registro R1, e também chamam a sub-rotina doadd. O “doadd” é o rótulo que contém o endereço do início da sub-rotina.
A sub-rotina consiste em apenas duas linhas. A primeira linha adiciona o conteúdo 3 de R ao conteúdo 10 de R0 o que permite o resultado de 13 em R0. A segunda linha com o opcode BX e o operando LR retorna da sub-rotina para o código chamador.
CERTO
O opcode RET no ARM 64 ainda lida com a sub-rotina, mas opera de maneira diferente do RTS em 6502 ou RET em x64, ou da combinação “BX LR” no ARM 64. No ARM 64, a sintaxe para RET é:
RETO {Xn}
Esta instrução dá a oportunidade para o programa continuar com uma sub-rotina que não é a sub-rotina chamadora, ou apenas continuar com alguma outra instrução e seu segmento de código seguinte. Xn é um registrador de uso geral que contém o endereço para o qual o programa deve continuar. Esta instrução ramifica incondicionalmente. O padrão é o conteúdo de X30 se Xn não for fornecido.
Padrão de Chamada de Procedimento
Se o programador quiser que seu código interaja com um código escrito por outra pessoa ou com um código produzido por um compilador, o programador precisa concordar com a pessoa ou com o escritor do compilador sobre as regras para uso do registro. Para a arquitetura ARM, essas regras são chamadas de Procedure Call Standard ou PCS. Estes são acordos entre duas ou três partes. O PCS especifica o seguinte:
- Quais registros µP são usados para passar os argumentos para a função (sub-rotina)
- Quais registradores µP são usados para retornar o resultado para a função que faz a chamada, conhecida como chamador
- Qual µP registra a função que está sendo chamada, conhecida como callee, pode corromper
- Quais registros µP o receptor não pode corromper
6.49 Interrupções
Existem dois tipos de circuitos controladores de interrupção disponíveis para o processador ARM:
- Controlador de interrupção padrão: O manipulador de interrupção determina qual dispositivo requer manutenção lendo um registro de bitmap do dispositivo no controlador de interrupção.
- Controlador de interrupção vetorial (VIC): Prioriza as interrupções e simplifica a determinação de qual dispositivo causou a interrupção. Após associar uma prioridade e um endereço de manipulador a cada interrupção, o VIC somente envia um sinal de interrupção ao processador se a prioridade de uma nova interrupção for maior que a do manipulador de interrupção atualmente em execução.
Observação : Exceção refere-se a erro. Os detalhes do controlador de interrupção vetorial para o computador ARM de 32 bits são os seguintes (64 bits é semelhante):
| Tabela 6.49.1 Exceção/interrupção de vetor ARM para computador de 32 bits |
|||
|---|---|---|---|
| Exceção/Interrupção | Forma abreviada | Endereço | Endereço Alto |
| Reiniciar | REINICIAR | 0x00000000 | 0xffff0000 |
| Instrução indefinida | UNDEF | 0x00000004 | 0xffff0004 |
| Interrupção de software | SWI | 0x00000008 | 0xffff0008 |
| Abortar pré-busca | pabt | 0x0000000C | 0xffff000C |
| Data do aborto | DABT | 0x00000010 | 0xffff0010 |
| Reservado | – | 0x00000014 | 0xffff0014 |
| Solicitação de interrupção | IRQ | 0x00000018 | 0xffff0018 |
| Solicitação de interrupção rápida | FIQ | 0x0000001C | 0xffff001C |
Este se parece com o arranjo para a arquitetura 6502 onde MNI , BR , e IRQ pode ter ponteiros na página zero e as rotinas correspondentes estão no alto da memória (ROM OS). Breves descrições das linhas da tabela anterior são as seguintes:
REINICIAR
Isso acontece quando o processador é ligado. Ele inicializa o sistema e configura as pilhas para diferentes modos de processador. É a exceção de maior prioridade. Ao entrar no manipulador de reinicialização, o CPSR está no modo SVC e os bits IRQ e FIQ são definidos como 1, mascarando quaisquer interrupções.
DATA DO ABORTO
A segunda maior prioridade. Isso acontece quando tentamos ler/escrever em um endereço inválido ou acessar a permissão de acesso errada. Ao entrar no Data Abort Handler, os IRQs serão desabilitados (I-bit set 1) e o FIQ será habilitado. Os IRQs são mascarados, mas os FIQs são mantidos desmascarados.
FIQ
A interrupção de prioridade mais alta, IRQ e FIQs, são desabilitadas até que o FIQ seja tratado.
IRQ
A interrupção de alta prioridade, o manipulador de IRQ, é inserida somente se não houver FIQ e anulação de dados em andamento.
Abortar pré-busca
Isso é semelhante à anulação de dados, mas ocorre em caso de falha na busca de endereço. Após a entrada no manipulador, os IRQs são desabilitados, mas os FIQs permanecem habilitados e podem acontecer durante uma anulação da pré-busca.
SWI
Uma exceção de interrupção de software (SWI) ocorre quando a instrução SWI é executada e nenhuma das outras exceções de prioridade mais alta foi sinalizada.
Instrução indefinida
A exceção de Instrução Indefinida ocorre quando uma instrução que não está no conjunto de instruções ARM ou Thumb atinge o estágio de execução do pipeline e nenhuma das outras exceções foi sinalizada. Esta é a mesma prioridade do SWI, pois pode acontecer de cada vez. Isso significa que a instrução que está sendo executada não pode ser uma instrução SWI e uma instrução indefinida ao mesmo tempo.
Tratamento de exceções ARM
Os seguintes eventos ocorrem quando ocorre uma exceção:
- Armazene o CPSR no SPSR do modo de exceção.
- O PC é armazenado no LR do modo de exceção.
- O registrador de link é definido para um endereço específico com base na instrução atual. Por exemplo: para ISR, LR = última instrução executada + 8.
- Atualize o CPSR sobre a exceção.
- Defina o PC para o endereço do manipulador de exceções.
6.5 Instruções e Dados
Dados referem-se a variáveis (rótulos com seus valores) e arrays e outras estruturas semelhantes a array. A string é como uma matriz de caracteres. Uma matriz de inteiros é vista em um dos capítulos anteriores. As instruções referem-se aos opcodes e seus operandos. Um programa pode ser escrito com os opcodes e os dados misturados em uma seção contínua da memória. Essa abordagem tem desvantagens, mas não é recomendada.
Um programa deve ser escrito primeiro com as instruções, seguidas pelos dados (plural de datum são dados). A separação entre as instruções e os dados pode ser de apenas alguns bytes. Para um programa, tanto as instruções quanto os dados podem estar em uma ou duas seções separadas na memória.
6.6 A Arquitetura de Harvard
Um dos primeiros computadores é chamado Harvard Mark I (1944). Uma arquitetura Harvard estrita usa um espaço de endereço para instruções de programa e um espaço de endereço diferente e separado para dados. Isso significa que existem duas memórias separadas. O seguinte mostra a arquitetura:
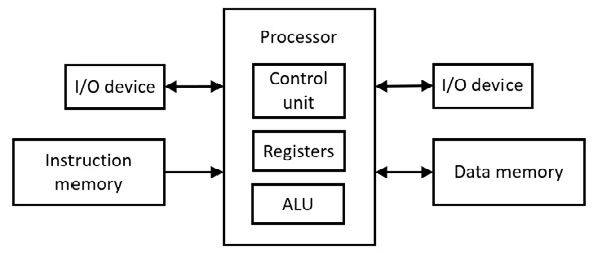
Figura 6.71 Arquitetura Harvard
A Unidade de Controle faz a decodificação das instruções. A Unidade Lógica Aritmética (ALU) realiza as operações aritméticas com lógica combinacional (portas). ALU também realiza operações lógicas (por exemplo, mudança).
Com o microprocessador 6502, uma instrução vai primeiro para o microprocessador (unidade de controle) antes que o dado (singular para dados) vá para o registro µP antes de interagirem. Isto requer pelo menos dois pulsos de clock e não é um acesso simultâneo à instrução e ao dado. Por outro lado, a arquitetura Harvard fornece acesso simultâneo às instruções e dados, com instrução e dados entrando no µP ao mesmo tempo (opcode para unidade de controle e dados para registro µP), economizando pelo menos um pulso de clock. Esta é uma forma de paralelismo. Esta forma de paralelismo é usada no cache de hardware em placas-mãe modernas (consulte a discussão a seguir).
6.7 Memória Cache
Memória Cache (RAM) é uma região de memória de alta velocidade (em comparação com a velocidade da memória principal) que armazena temporariamente as instruções ou dados do programa para uso futuro. A memória cache opera mais rápido que a memória principal. Geralmente, essas instruções ou itens de dados são recuperados da memória principal recente e provavelmente serão necessários novamente em breve. O objetivo principal da memória cache é aumentar a velocidade de acesso repetido aos mesmos locais da memória principal. Para ser eficaz, o acesso aos itens armazenados em cache deve ser significativamente mais rápido do que o acesso à fonte original das instruções ou dados, conhecida como Backing Store.
Quando o cache está em uso, cada tentativa de acessar um local da memória principal começa com uma busca no cache. Se o item solicitado estiver presente, o processador o recupera e utiliza imediatamente. Isso é chamado de acerto de cache. Se a busca no cache não for bem-sucedida (uma falha no cache), a instrução ou item de dados deverá ser recuperado do armazenamento de apoio (memória principal). No processo de recuperação do item solicitado, uma cópia é adicionada ao cache para uso previsto em um futuro próximo.
Unidade de gerenciamento de memória
A Unidade de Gerenciamento de Memória (MMU) é um circuito que gerencia a memória principal e registros de memória relacionados na placa-mãe. No passado, era um circuito integrado separado na placa-mãe; mas hoje normalmente faz parte do microprocessador. A MMU também deve gerenciar o cache (circuito) que hoje também faz parte do microprocessador. O circuito cache é um circuito integrado separado no passado.
RAM estática
A RAM estática (SRAM) tem um tempo de acesso substancialmente mais rápido que a DRAM, embora às custas de circuitos significativamente mais complexos. As células de bits SRAM ocupam muito mais espaço na matriz do circuito integrado do que as células de um dispositivo DRAM que é capaz de armazenar uma quantidade equivalente de dados. A memória principal (RAM) normalmente consiste em DRAM (RAM Dinâmica).
A memória cache melhora o desempenho do computador porque muitos algoritmos executados por sistemas operacionais e aplicativos exibem a localidade de referência. A Localidade de Referência refere-se ao reaproveitamento de dados que foram acessados recentemente. Isso é conhecido como localidade temporal. Em uma placa-mãe moderna, a memória cache está no mesmo circuito integrado do microprocessador. A memória principal (DRAM) está distante e acessível através dos barramentos. A Localidade de Referência também se refere à localidade espacial. A localidade espacial tem a ver com a maior velocidade de acesso aos dados devido à proximidade física.
Via de regra, as regiões de memória cache são pequenas (em número de localizações de bytes) em comparação com o armazenamento de apoio (memória principal). Os dispositivos de memória cache são projetados para velocidade máxima, o que geralmente significa que eles são mais complexos e caros por bit do que a tecnologia de armazenamento de dados usada no armazenamento de apoio. Devido ao seu tamanho limitado, os dispositivos de memória cache tendem a encher rapidamente. Quando um cache não possui um local disponível para armazenar uma nova entrada, uma entrada mais antiga deve ser descartada. O controlador de cache usa uma Política de Substituição de Cache para selecionar qual entrada de cache será substituída pela nova entrada.
O objetivo da memória cache do microprocessador é maximizar a porcentagem de ocorrências no cache ao longo do tempo, proporcionando assim a maior taxa sustentada de execução de instruções. Para atingir esse objetivo, a lógica de cache deve determinar quais instruções e dados serão colocados no cache e retidos para uso futuro próximo.
A lógica de cache de um processador não tem garantia de que um item de dados em cache será usado novamente depois de inserido no cache.
A lógica do cache depende da probabilidade de que, devido à localidade temporal (repetição ao longo do tempo) e espacial (espaço), haja uma boa chance de que os dados armazenados em cache sejam acessados em um futuro próximo. Em implementações práticas em processadores modernos, os acessos ao cache normalmente ocorrem em 95 a 97 por cento dos acessos à memória. Como a latência da memória cache é uma pequena fração da latência da DRAM, uma alta taxa de acertos do cache leva a uma melhoria substancial no desempenho em comparação com um design sem cache.
Algum paralelismo com cache
Conforme mencionado anteriormente, um bom programa na memória possui as instruções separadas dos dados. Em alguns sistemas de cache, existe um circuito de cache à “esquerda” do processador e outro circuito de cache à “direita” do processador. O cache esquerdo trata as instruções de um programa (ou aplicativo) e o cache direito trata os dados do mesmo programa (ou mesmo aplicativo). Isso leva a um melhor aumento de velocidade.
6.8 Processos e Threads
Tanto os computadores CISC quanto os RISC possuem processos. Um processo está no software. Um programa em execução (em execução) é um processo. O sistema operacional vem com seus próprios programas. Enquanto o computador está em operação, os programas do sistema operacional que permitem o funcionamento do computador também estão em execução. Estes são processos do sistema operacional. O usuário ou programador pode escrever seus próprios programas. Quando o programa do usuário está em execução, é um processo. Não importa se o programa é escrito em linguagem assembly ou em linguagem de alto nível como C ou C++. Todos os processos (usuário ou SO) são gerenciados por outro processo denominado “agendador”.
Um thread é como um subprocesso pertencente a um processo. Um processo pode ser iniciado e dividido em threads e continuar como um processo. Um processo sem threads pode ser considerado o thread principal. Os processos e seus threads são gerenciados pelo mesmo escalonador. O próprio agendador é um programa quando reside no disco do sistema operacional. Ao executar na memória, o agendador é um processo.
6.9 Multiprocessamento
Threads são gerenciados quase como processos. Multiprocessamento significa executar mais de um processo ao mesmo tempo. Existem computadores com apenas um microprocessador. Existem computadores com mais de um microprocessador. Com um único microprocessador, os processos e/ou threads usam o mesmo microprocessador de maneira intercalada (ou divisão de tempo). Isso significa que um processo utiliza o processador e para sem terminar. Outro processo ou thread usa o processador e para sem terminar. Então, outro processo ou thread utiliza o microprocessador e para sem terminar. Isso continua até que todos os processos e threads enfileirados pelo escalonador tenham compartilhamento do processador. Isso é conhecido como multiprocessamento simultâneo.
Quando há mais de um microprocessador, ocorre um multiprocessamento paralelo, em oposição à simultaneidade. Nesse caso, cada processador executa um processo ou thread específico, diferente daquele que o outro processador está executando. Todos os processadores na mesma placa-mãe executam seus diferentes processos e/ou diferentes threads ao mesmo tempo em multiprocessamento paralelo. Os processos e threads no multiprocessamento paralelo ainda são gerenciados pelo agendador. O multiprocessamento paralelo é mais rápido que o multiprocessamento simultâneo.
Neste ponto, o leitor pode estar se perguntando como o processamento paralelo é mais rápido que o processamento simultâneo. Isso ocorre porque os processadores compartilham (têm que usar em momentos diferentes) a mesma memória e portas de entrada/saída. Pois bem, com o uso do cache, o funcionamento geral da placa-mãe fica mais rápido.
6.10 Paginação
A Unidade de Gerenciamento de Memória (MMU) é um circuito próximo ao microprocessador ou no chip do microprocessador. Ele lida com o mapa de memória ou paginação e outros problemas de memória. Nem o computador 6502 µP nem o Commodore-64 possuem uma MMU per se (embora ainda haja algum gerenciamento de memória no Commodore-64). O Commodore-64 lida com a memória paginando onde cada página tem 256 10 bytes de comprimento (100 16 bytes de comprimento). Não era obrigatório manipular a memória por paginação. Ele ainda poderia ter apenas um mapa de memória e, em seguida, programas que se encaixassem em suas diferentes áreas designadas. Bem, a paginação é uma forma de fornecer um uso eficiente da memória sem ter muitas seções de memória que não podem conter dados ou programa.
A arquitetura de computador x86 386 foi lançada em 1985. O barramento de endereços tem 32 bits de largura. Então, um total de 2 32 = 4.294.967.296 espaço de endereço é possível. Este espaço de endereço é dividido em 1.048.576 páginas = 1.024 KB de páginas. Com esse número de páginas, uma página consiste em 4.096 bytes = 4 KB. A tabela a seguir mostra as páginas de endereço físico para a arquitetura x86 de 32 bits:
| Tabela 6.10.1 Páginas endereçáveis físicas para a arquitetura x86 |
||
|---|---|---|
| Endereços Base 16 | Páginas | Endereços Base 10 |
| FFFFF000 – FFFFFFFF | Página 1.048.575 | 4.294.963.200 – 4.294.967.295 |
| FFFFE000 – FFFFEFFF | Página 1.044.479 | 4.294.959.104 – 4.294.963.199 |
| FFFFD000 – FFFFDFFF | Página 1.040.383 | 4.294.955.008 – 4.294.959.103 |
| | | | |
| | | |
| | | |
| 00002000 – 00002FFF | Página 2 | 8.192 – 12.288 |
| 00001000 – 00001FFF | Página 1 | 4.096 – 8.191 |
| 00000000 – 00000FFF | Página 0 | 0 – 4.095 |
Um aplicativo hoje consiste em mais de um programa. Um programa pode ocupar menos de uma página (menos de 4.096) ou duas ou mais páginas. Portanto, um aplicativo pode ocupar uma ou mais páginas, onde cada página tem 4.096 bytes. Diferentes pessoas podem escrever um aplicativo, com cada pessoa atribuída a uma ou mais páginas.
Observe que a página 0 vai de 00000000H a 00000FFF
a página 1 é de 00001000H a 00001FFFH, a página 2 é de 00002000 H – 00002FFF H , e assim por diante. Para um computador de 32 bits, existem dois registradores de 32 bits no processador para endereçamento físico da página: um para o endereço base e outro para o endereço de índice. Para acessar as localizações dos bytes da página 2, por exemplo, o registro do endereço base deve ser 00002 H que são os primeiros 20 bits (da esquerda) para os endereços iniciais da página 2. O resto dos bits no intervalo de 000 H para FFF H estão no registro denominado “registro de índice”. Assim, todos os bytes da página podem ser acessados apenas incrementando o conteúdo no registrador de índice de 000 H para FFF H . O conteúdo do registrador de índice é adicionado ao conteúdo que não muda no registrador base para obter o endereço efetivo. Este esquema de endereçamento de índice é válido para as outras páginas.
No entanto, não é assim que o programa em linguagem assembly é escrito para cada página. Para cada página, o programador escreve o código começando na página 000 H para a página FFF H . Como o código em páginas diferentes está conectado, o compilador usa o endereçamento de índice para conectar todos os endereços relacionados em páginas diferentes. Por exemplo, supondo que a página 0, a página 1 e a página 2 sejam para um aplicativo e cada uma tenha o 555 H endereço que está conectado um ao outro, o compilador compila de tal forma que quando 555 H da página 0 deve ser acessada, 00000 H estará na base cadastral e 555 H estará no registro do índice. Quando 555 H da página 1 deve ser acessada, 00001 H estará na base cadastral e 555 H estará no registro do índice. Quando 555 H da página 2 deve ser acessada, 00002 H estará no registrador base e 555H estará no registrador de índice. Isso é possível porque os endereços podem ser identificados por meio de rótulos (variáveis). Os diferentes programadores têm que concordar com o nome dos rótulos a serem usados para os diferentes endereços de conexão.
Memória Virtual de Página
A paginação, conforme descrito anteriormente, pode ser modificada para aumentar o tamanho da memória em uma técnica chamada “Page Virtual Memory”. Supondo que todas as páginas da memória física, conforme descrito anteriormente, contenham algo (instruções e dados), nem todas as páginas estão ativas no momento. As páginas que não estão ativas no momento são enviadas para o disco rígido e substituídas pelas páginas do disco rígido que precisam estar em execução. Dessa forma, o tamanho da memória aumenta. À medida que o computador continua a funcionar, as páginas que ficam inativas são trocadas pelas páginas do disco rígido, que ainda podem ser as páginas que foram enviadas da memória para o disco. Tudo isso é feito pela Unidade de Gerenciamento de Memória (MMU).
6.11 Problemas
O leitor é aconselhado a resolver todos os problemas de um capítulo antes de passar para o próximo capítulo.
1) Cite as semelhanças e diferenças entre as arquiteturas de computador CISC e RISC. Cite um exemplo de computador SISC e RISC.
2) a) Quais são os seguintes nomes para o computador CISC em termos de bits: byte, palavra, palavra dupla, palavra quádrupla e palavra quádrupla dupla.
b) Quais são os seguintes nomes para o computador RISC em termos de bits: byte, meia palavra, palavra e palavra dupla.
c) Sim ou Não. Palavra dupla e palavra quádrupla significam a mesma coisa nas arquiteturas CISC e RISC?
3 a) Para x64, o número de bytes para as instruções em linguagem assembly varia de quê a quê?
b) O número de bytes para todas as instruções em linguagem assembly para o ARM 64 é fixo? Se sim, qual é o número de bytes para todas as instruções?
4) Liste as instruções de linguagem assembly mais comumente usadas para x64 e seus significados.
5) Liste as instruções em linguagem assembly mais comumente usadas para ARM 64 e seus significados.
6) Desenhe um diagrama de blocos rotulados do antigo computador Harvard Architecture. Explique como suas instruções e recursos de dados são usados no cache dos computadores modernos.
7) Diferencie entre um processo e um thread e dê o nome do processo que trata dos processos e threads na maioria dos sistemas de computador.
8) Explique resumidamente o que é multiprocessamento.
9) a) Explique a paginação conforme aplicável à arquitetura de computador x86 386 µP.
b) Como essa paginação pode ser modificada para aumentar o tamanho de toda a memória?